HiP(Hirarchical Perceiver) review
Hierarchical Perceiver, 2022
Summary
이번에 살펴본 논문은 Hierarchical Perceiver(HiP) 라는 논문입니다. 기존의 Perceiver 모델이 Transformer 기반의 모델 구조, cross attention을 통해 다양한 modality를 다룰 수 있었습니다. 한편, High resolution을 가진 Image, Video 등의 입력에 대해서는 처리가 어려운 문제점을 지적합니다. 따라서 그에 대한 해결책으로 Hierarchical Perceiver (이하 HiP)를 제안합니다. HiP에서는 flatten operation을 통해서 input을 각 그룹으로 나누어, locality를 보존시키며 연산을 수행합니다. 각 그룹은 permutation invariant한 특성을 이용해 다시 merge하게 됩니다. 또한 large input에 대해서도 dense low-dimensional position embedding을 학습하기 위해 Masked Auto Encoding(MAE) self-supervied learning을 활용합니다. Masked Autoencoders Are Scalable Vision Learners 논문에서 제시한 “masking을 활용한 pretrain이 여러 finetuning task에 효율적이다.”라는 점을 본 논문에서도 학습에 활용하였습니다. 이를 통해 ImageNet, Audioset, PASCAL VOC 에서 기존의 Perceiver 대비 더 나은 정확도와 효율성을 보이고 있습니다.
Main Idea
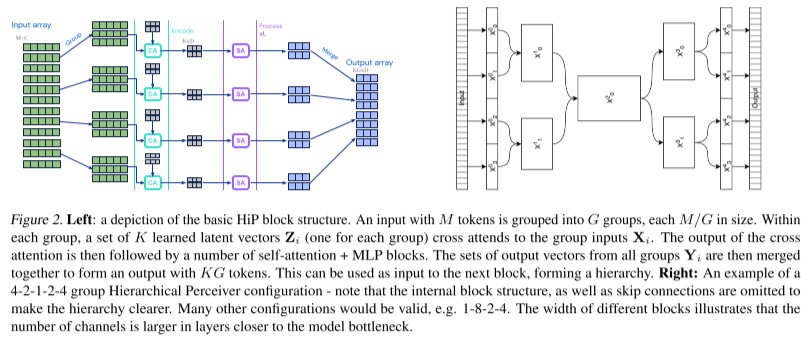
위 사진의 왼쪽 그림은 기본적인 HiP 블록에 대한 구조를 보여줍니다. large size input 에 대해 locality를 보존하기 위해서 flattening을 사용하고 있습니다. flattening은 large 입력에 대해서 순서대로 특정 size만큼 잘라서 stack 형식으로 쌓기 때문에 어느 정도의 locality가 보존되는 특성이 있습니다. flattening을 통해 G 개의 group을 형성하고, local input으로 나누어 연산하고, 추후 병합 해줍니다. Transformer의 attention 연산은 input token에 대해 invariant한 특성이 있기 때문에 이러한 과정이 타당하다고 볼 수 있습니다.
각 그룹에서는 M/G tokens, C channel 들로 구성되어 Perceiver 의 모델구조와 동일하게 encoding (local input과 latent vector의 cross attention), processing (응축된 latent vector의 self attnetion), merge (local process 값들을 merge) 과정을 수행해 줍니다. merge된 출력 값은 next block의 입력으로 활용됩니다.
오른쪽 그림은 4-2-1-2-4 group의 hierarchical 한 구조를 잘 보여주기 위한 모식도입니다. 각각 grouping이 4개 group, 2개 group, 1개 group에서 다시 2개 gorup, 4개 group, output으로 복원의 구조를 보여줍니다.
- Laerned low-dimensional positional embeddings

위의 이미지는 왼쪽부터 순서대로 원본 이미지, 85% 비율의 groupwise-masking 이미지, 16-group model을 통한 output 복원 이미지를 나타냅니다. input tensor에 random & uniform mask 처리를 하고, decoder를 통해 나온 출력이 가려진 부분을 맞추는 식으로 positional embedding을 학습합니다. pretrain 과정은 Masked Autoencoders Are Scalable Vision Learners 의 부분과 유사하게 진행되며, masking rate, hyperparameter 부분은 HiP setting에 맞게 수정하여 학습하였습니다.
Experiements
-
Comparison to state-of-the-art
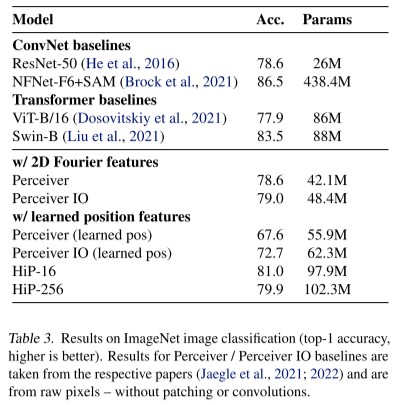
위의 테이블은 ImageNet image classification(top-1 accuracy)에 대한 결과를 보여줍니다. image classification task에서는 HiP 모델의 encoder부분만을 활용합니다. 타 모델에 비해 outperformance를 이루고 있지는 않지만, Perceiver 모델에 비해서는 좋은 성능을 보이고 있습니다. HiP-16은 81%, HiP-256은 79.9%의 정확도를 보이고 있습니다. 여기서 HiP-16과 HiP-256의 차이는 sub-block의 개수를 16개로 나누어 진행되는지, 256개의 block으로 나누어 진행되는지에 따라 달라집니다. input size가 더 클 경우에는 Hip-256을 사용하고는 합니다. (i.e. audio-visual inputs) -
Training steps per second
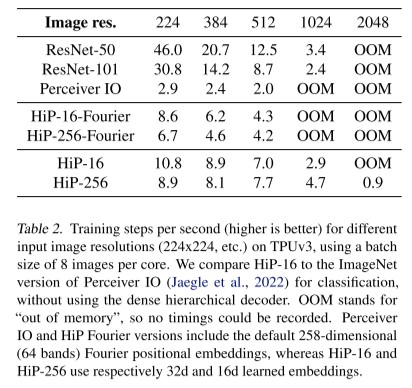
위의 Table에서는 image resolution에 따른 초당 training step을 보여줍니다. (높을수록 좋은 값) TPUv3에서 각 코어마다 8개의 이미지를 batch size로 활용하였고, HiP에서 hierarchical decoder block은 활용하지 않은 결과입니다. (즉, decoder block을 포함한 trainint step/sec 은 아닌 것입니다.) Perceiver IO 에 비해서 더 높은 resolution에서 더 빠른 학습 과정을 보여주고 있습니다. 또한 타모델의 경우 high resolution 입력에 대해 Out Of Memory가 발생하는데, HiP-256의 경우 training이 가능한 것을 보여주고 있습니다. -
Ablations: MAE vs no MAE & importance of local structure
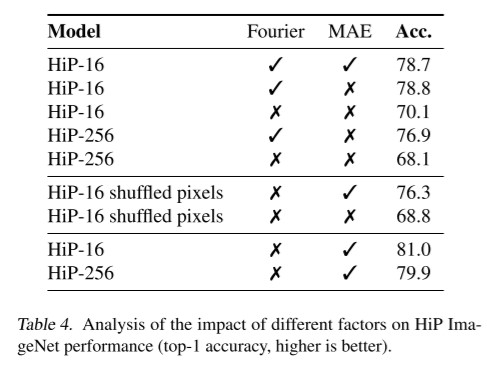
위의 결과에서는 learned positional embedding을 사용할 때, masked auto-encoding(MAE)을 활용하였을 경우와 그렇지 않았을 경우의 성능을 비교합니다. MAE를 사용하였을 때는 사용하지 않았을 경우에 비해 현저하게 성능이 개선되는 것을 확인해 볼 수 있습니다. 한편, MAE없이 Fourier positional embedding을 경우에도, MAE를 사용하였을 경우와 비슷한 성능을 보입니다. MAE를 통해 low-dimensional positional embedding을 학습이 성능 향상에 기여했다는 점을 보여줍니다.
Discussion
- Connectivity learning
Perceiver, Transformer는 global attention을 통해 전체적인 부분을 배울 수 있지만, local한 부분에서는 약점을 가지고 있습니다. 반면, HiP는 local group을 취함으로써 local 한 정보도 취하고, encoder-decoder 구조 상에서 global한 soft-connectivity 의 여지를 남겨두고 있습니다. - The need for self-supervised pre-training
단순히 classification loss만을 통해서 high-resolution sample에 대해 learned embedding을 학습시키는 것은 역부족이었습니다. 이를 위해서 dense masked auto-encoding 을 활용하였고, 우수한 positional embedding을 배운 것을 보였습니다. - Many samll inputs
각각의 modality 마다 dimensionalty가 다르고, resolution이 다릅니다. 따라서 본 논문에서는 동일한 dimensionality를 가진 latent vector들에 projection 시키고, learned embedding을 함께 추가해주는 식으로 진행되었습니다. - Augmentation: the last bastion of domain knowledge?
본 논문에서는 다른 preprocessing 또는 prior knowledge의 삽입을 최소화하였는데, data augmentation 은 sample의 insufficiency 때문에 수행해 주었습니다.