Perceiver IO review
Perceiver IO, A General Architecture for Structured Inputs & Outputs, 2021
Summary
이번에 포스팅할 논문은 Perceiver IO: A General Architecture for Structured Inputs & Outputs 입니다. Perceiver IO는 Perceiver의 출력이 단순히 classification과 같은 단순한 task에 국한되는 점을 보완하여, 다양한 structure의 Input과 Output을 가질 수 있도록 개선된 모델구조를 가지고 있습니다. (이전 포스팅은 여기를 참고해 주세요) 그 방법을 간단하게 소개하자면, task별 Input에 대한 Query vector를 구성하여 Perceiver model 내부에서 얻어진 K,V 값과 사전에 구성해 둔 Query vector에 대한 cross attention을 수행하여 각 task에 맞는 size, semantic을 낼 수 있는 적절한 Output 값을 갖도록 학습합니다. 그 결과 Sintel optical flow estimation task 에서는 SOTA를 달성하고, GLUE 벤치마크에서는 input tokenization 없이 BERT baseline과 유사한 성능을 보이고 있습니다.
Main Idea
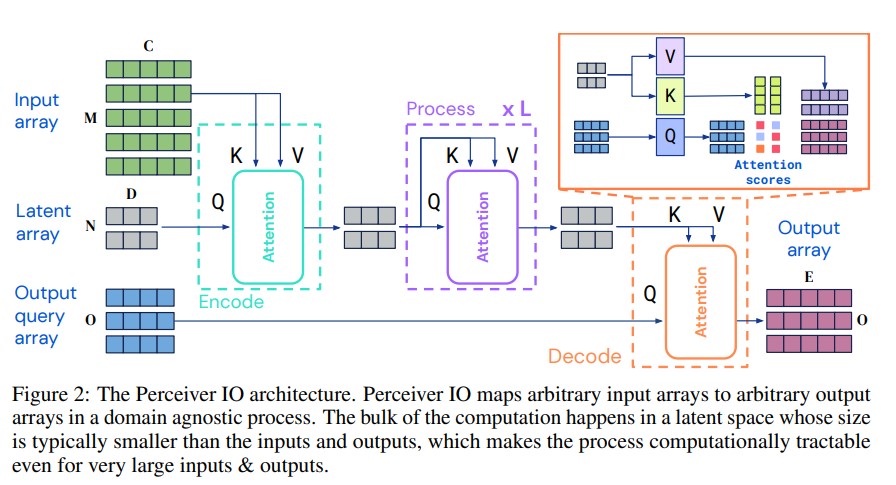
위의 그림은 Perceiver IO 의 모델구조입니다. Perceiver IO는 크게 Encoder, Process, Decoder라는 3 개의 module로 이루어진 구성입니다. Encoder에서는 Perceiver에서 large size와의 input과 cross attention을 수행하는 것과 동일하게 이루어 집니다. Process라는 과정에서도 Perceiver에서와 같이 latent Transformer를 거쳤던 것처럼 latent vector를 refine합니다. Perceiver와 달리 IO model에서는 Decode라는 부분이 새롭게 추가된 것인데요, 여기서는 latent vector에서 얻어진 K,V 값과 기존에 이미 구해둔 Output Query array를 Q로 하여 cross attention을 수행하게 됩니다. 해당 Q는 hand-desined, learned embeddings 또는 input에 대한 simple function 등으로 구성됩니다. 이러한 query vector와의 attention을 통해 적절한 shape, semantic을 가진 output을 뽑아내게 됩니다.
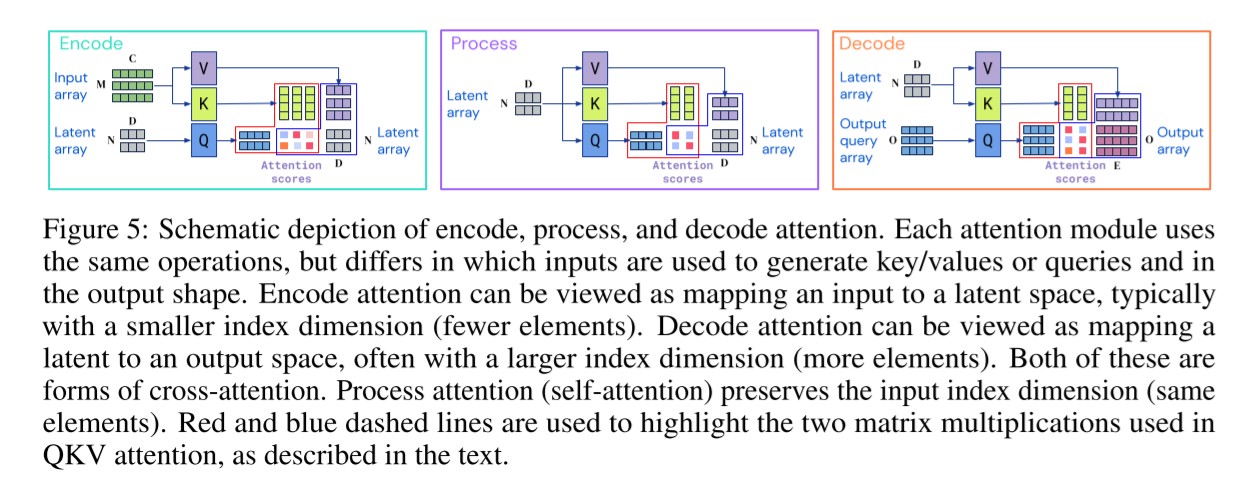
각 모듈에 대한 조금 더 상세한 과정은 위와 같습니다.

위의 그림은 각 modality마다 어떤 식으로 query array가 구성되는지를 보여줍니다. MLM 같은 경우는 단순하게 position embedding 정보만 주며, classification 같은 경우는 task id를 줍니다. Starcraft2 task에서는 entities에 대한 input features가 홀로 사용되고, Optical flow task에서는 Input faeture와 position feature가 함께 사용되고 있습니다. 또, heterogeneous outputs을 다뤄야 하는 경우에는, 각각의 modality 정보가 서로 concat하여 쿼리가 만들어 집니다.
Experiments
1. Laungage
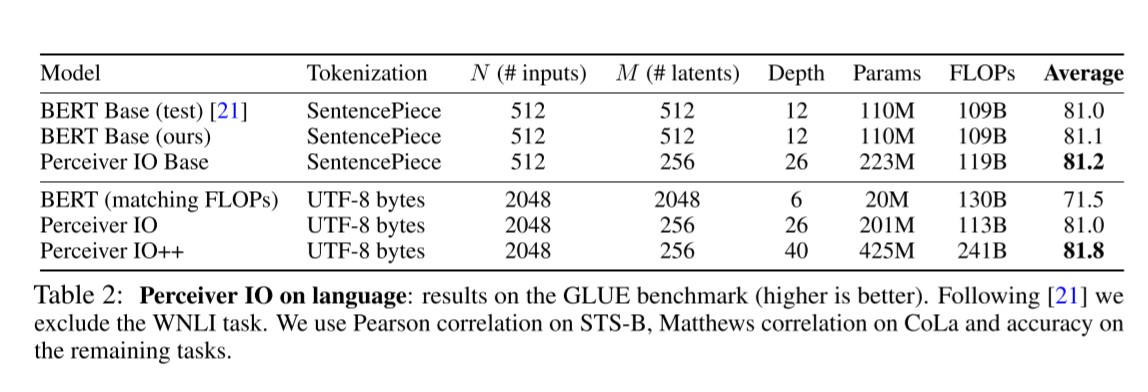
위의 Table은 GLUE benchmark 데이터셋에서 실험한 결과를 보여줍니다. (WNLI task는 제외) SenetencPiece tokenizer를 사용했을 때에는 Percevier IO모델이 아주 미세하게 조금 더 나은 성능을 보입니다. UTF-8 bytes 값을 그대로 입력으로 주었을 때에는 BERT보다 확실히 우수한 성능을 보여주는데요, 이는 본 모델의 장점으로 꼽는 tokenizer-free 한 특성을 보여주는 실험결과로 보입니다. 이를 통해 hand-crafted의 필요성을 줄이고 potentially harmful tokenization schemes를 제거할 수 있다고 말합니다. 모델의 pretraining method는 Wikipedia English + C4 dataset 에 대해서 BERT와 동일한 MLM(Masked Language Modeling) 방식을 활용합니다.
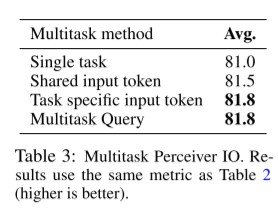
위의 결과는 8 GLUE benchmark task에 대해서 UTF-8 bytes를 raw directly input data를 활용하여서, 각기 다른 Multitask 방법에 따른 실험 결과를 보여줍니다. single task의 경우는 a special token 을 함께 넣어주며 각각의 모델이 독립적으로 학습한 결과를 보여줍니다. shared input token의 경우는 a single token이 모든 task들에 대해서 사용됩니다. task specific input token의 경우는, 각 task마다 명시적으로 차이를 주는 방식입니다. 이러한 방법은 BERT에서 [CLS] token을 적용하는 것과 비슷한 방법이라고 생각할 수 있습니다. 한편, 본 모델이 제안하는 Multitask Query 에서는 이러한 [CLS] 꼴의 토큰이 필요가 없이 우수한 성능을 보이고 있으며, task의 수가 매우 많아질 때에는 더 매력적인 강점이 되게 됩니다.
2. Optical flow
Optical flow task는 비디오의 연속적인 두 프레임의 이미지 사이에서 각 pixel 사이의 2D displacement를 예측하는 task입니다. optical flow는 navigation, visual odometry(시각적 주행거리 예측(?)), 3D geometry 예측, 3D human pose estimation 등 넓은 application 범주를 가지고 있습니다. Optical flow가 현재 뉴럴넷에 대해 challenging 하다고 하는데요, 그 이유는 1) Optical flow는 대응 관계에 의존하기 때문입니다. a single frame은 flow에 대한 정보를 제공하지 않으며, 완전히 서로 다른 이미지가 동일한 ground truth flow를 생성할 수도 있다고 합니다. 2) flow를 annotation하는 게 매우 어렵기 때문입니다. (AutoFlow같은 dataset이 있기는 하지만) image가 realistic하고 high-quality의 ground truth를 가진 데이터셋은 작고, biased 되어 있다고 논문에서 언급하고 있습니다.
optical flow estimation task 를 위해서는, 1) points 사이의 대응 관계를 찾아야 하고, 2) 점들 사이의 상대적인 offset을 계산하고, 3) estimated flow를 image의 넓은 공간에 전파해야 합니다. 이러한 여러 과정을 위해 연구자들은 specific한 architecture model들을 제안하고는 하였습니다.
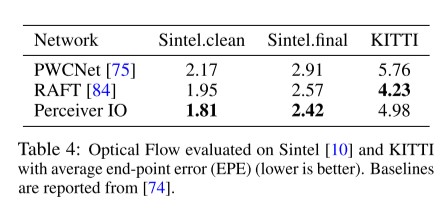
위의 결과는 SOTA를 달성하고 있는 Network 들과 결과를 비교한 부분입니다. Perceiver IO 는 위에서 언급한 그런 step들을 수행하지 않고 straightforward 라게 입력을 취하고 있습니다. 두 프레임을 channel dimension에 따라 concatenate 하였고, 각 픽셀을 중심으로 한 3x3 patch를 추출하여 입력으로 줍니다. (3x3 patch를 쓰면 inductive bias가 생길 수 있어, 본 논문에서 patch를 사용하지 않고 진행한 ablaion study를 진행합니다. patch를 사용하지 않았을 때는, 거의 유사하나 patch를 사용했을 때보다 아주 미세하게 성능이 조금 저조합니다.) 위의 여러 과정을 거치는 SOTA 모델에 비해 비교적 단순한 방법으로 compatible한 성능을 보여주고 있습니다.
3. Multimodal autoencoding
Multimodal autoencoding에서는 Kinetics-700-2020 dataset을 활용하여 image, audio, class label을 reconstruction합니다.

위의 사진은 image, audio가 각각 reconstruction 된 것을 보여줍니다. Perceiver IO 에서는 입력에 각각의 modality 별로 modality-specigfic embeddings를 넣어주어 각 modality를 구분해 주고, 모든 입력을 2D array로 serialization하는 방식을 사용합니다. 쿼리로는 Fourier-based position embedding을 사용합니다.
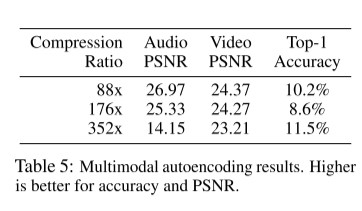
위는 각 오디오, 비디오, class label의 예측 정도를 보여줍니다. latent variable들이 modality사이에서 shared 되어 있고, 명시적으로 할당되어 있지 않기 때문에 각 modality 사이의 reconstruction quality가 loss term의 weight에 의해 trade off 관계가 있다고 말합니다. 본 실험에서는 accuracy를 낮추고, PSNR을 높이는 쪽을 선택했습니다. accuracy에 중점을 둔 실험에서는 비디오 20.7 PSNR을 가지며, Top-1 45%의 정확도를 보여줍니다.
4. StarCraft II
StarCraft 게임을 운영하는 AlphaStar라는 SOTA system에서 agent unit selection policy를 돕는 부분에서 Tranformer가 사용됩니다. 한편, 여기서 이 Transformer를 Perceiver IO로 대체했을 때에도 동일한 수준의 승률을 보여줍니다.
5. Image Classification
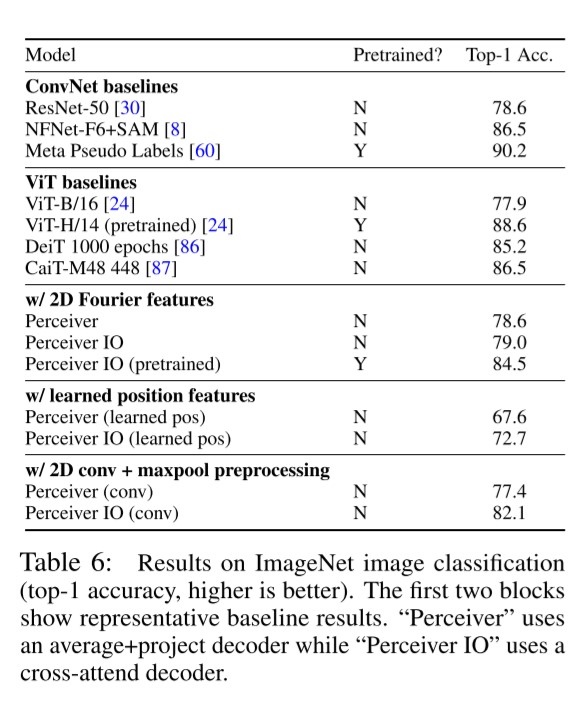
마지막으로 ImageNet에 대한 이미지 분류 실험 결과입니다. 실험 결과 표의 위의 두 블록은 순서대로 ConvNet 기반의 모델들, ViT기반의 모델들의 성능을 보여줍니다. 아래의 세 블록에서는 각각 어떤 Feature를 함께 사용했냐에 따라 Perceiver, Perceiver IO 의 성능을 비교하며 보여주고 있습니다. 비록 Conv based, ViT based model의 성능에는 크게 미치지 못하지만, 2D architecture가 없거나 feature information을 따로 사용하지 않았을 경우에는 best result를 보여주고 있습니다.
Reference
The End
- 다양한 IO를 다룰 수 있게 되었다는 점이 인상깊은 논문이었다.
- 정확한 쿼리로 정확한 information을 retrieval하기 위함이지만, 그럼에도 hand-desined한 query를 줘야 한다는 것이 결국은 조금 아직은 사람을 손을 타야 하는 것인가 하는 생각이 들었다. (더 나은 genral query를 줄 수 있는 후속 연구가 나올 거 같은 느낌?)
- 왜 잘 되지? 에 대해 조금 더 생각해 봤다. Perceiver와 동일한 구조인데 단순히 decoding 과정만 추가해서 잘 된거라면, 논문에서 언급한 대로 Query array가 효율적이었을 것으로 보인다. 그럼 Query array를 어떻게 주냐에 따라서 더 나은 output을 만들어 낼수도 있다는 말이 아닐까? 앞에서 했던 말의 반복인 것 같지만, more efficient and more general query array에 관한 모델이 나올 수도 있겠다는 생각이 든다.
- Starcraft II 의 AlphaStar의 agent unit selection policy를 결정짓는 pointer network을 대체하면서 한 실험에서는, ‘이런 다양한 데이터 모달리티를 포함함에도 결국은 이 조차도 general model이 되기 위한 하나의 module로서 쓰이는구나.’ 하는 생각이 들었다. 다양한 데이터 모달리티를 다루는 것은 ‘지능’의 전부가 아니라 ‘하나의 충분조건’이다 라는 느낌을 받은 부분이었다. 더 어려운 문제를 풀거나, 더 깊은 추론이 필요한 문제, 환경이 급변하는 등의 문제에서는 역시 RL이 필요한 것인가 하고. RL 게을리 하지 말자.