The Transformer Family
Short Summary about The Transformer Family
Vanila Transformer
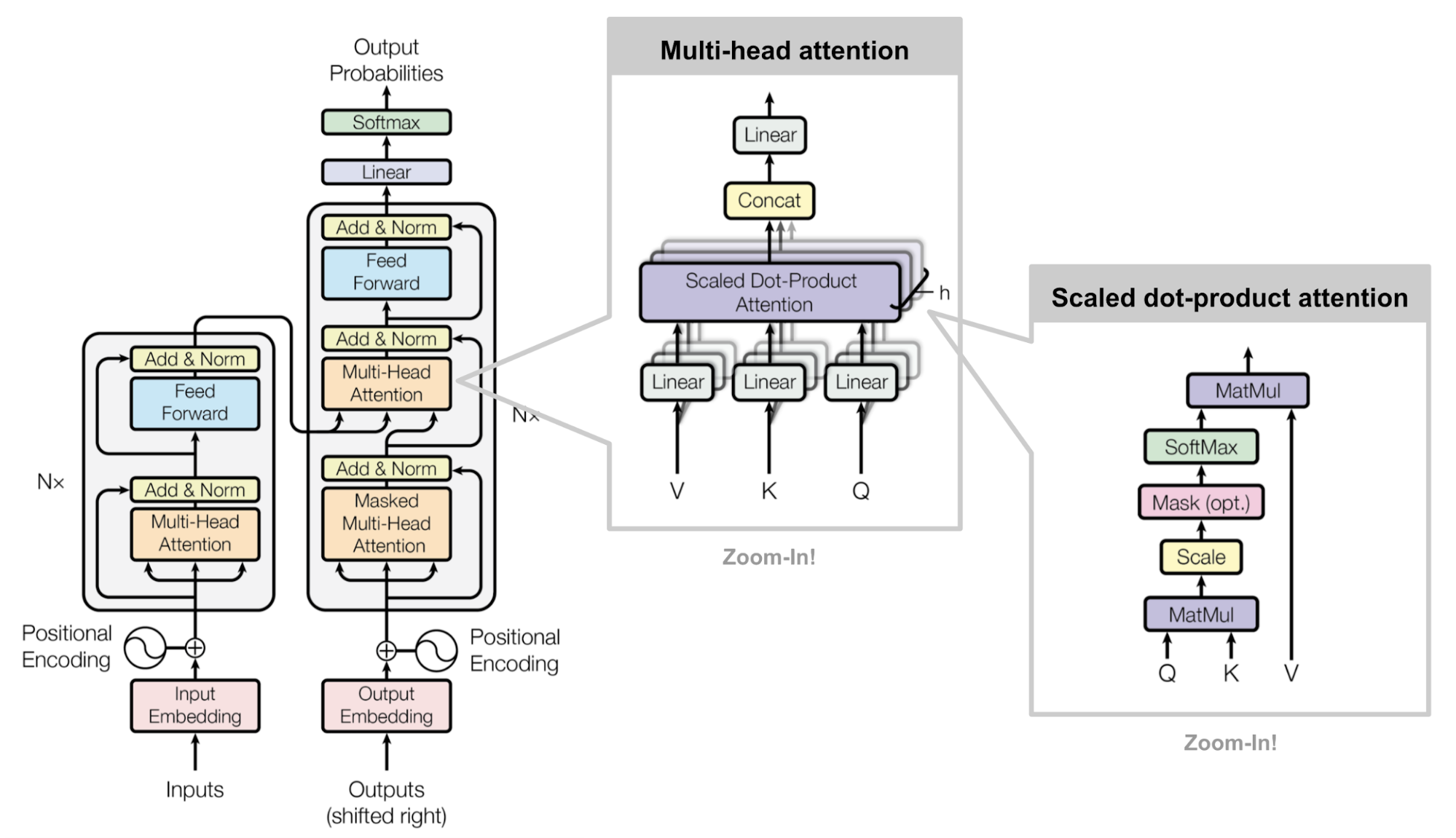
- self-attention is applied in each encoder and decoer.
- cross-attention is applied between encoder and decoder.
- dot(Query vector, Key vector) = attention score.
- and then dot(attention score, Value vector) = attention value.
- No long term dependency
Linformer
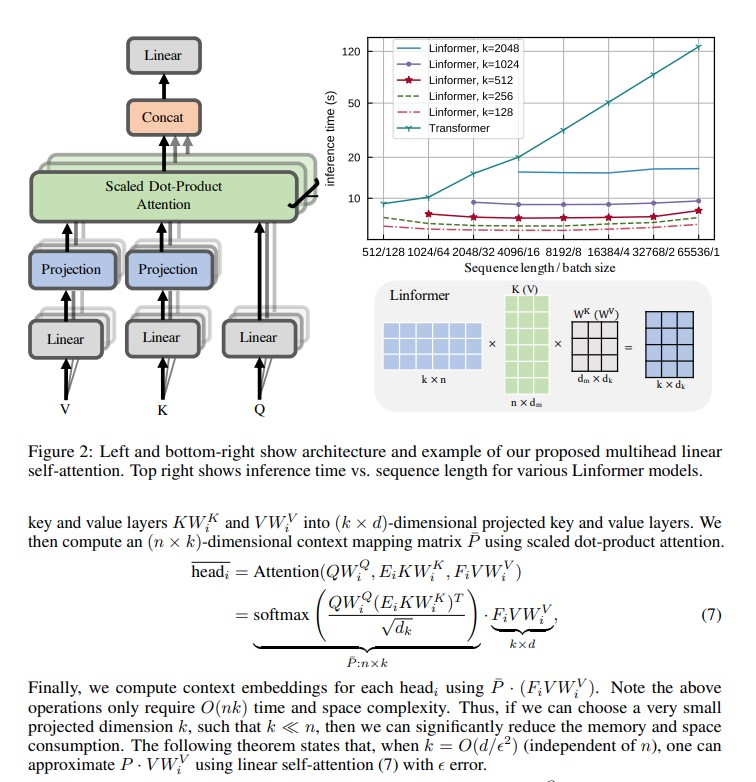
Reference
- https://lilianweng.github.io/posts/2020-04-07-the-transformer-family/
- Linformer