Sentence-BERT 논문 리뷰
Sentence-BERT, Sentence Embeddings using Siamese BERT-Networks (2019) review
Abstract
- BERT 가 sentence-pair regression task (STS와 같은) 에서 우수한 성능을 보이고 있지만, 만약 10,000개의 sentences 에 대해 most similar pair를 얻기 위해서는 약 65시간이 소요
- 본 논문에서는 pretrained bert 모델의 modification 을 활용한 sentecne-BERT 를 소개
- siamese and triplet network structure를 BERT/RoBERTa 기반으로 취함
- cosine simliarity 를 통해 비교가능한 semantically meaningful sentence embeddings 를 얻을 수 있음
- BERT/RoBERTa 기반의 SBERT를 활용하여 inference time 을 about 65 hours -> 5 seconds 로 감소 && 성능 유지
- STS tasks 와 transfer laerning 에서 타 sentence embedding methods 에 비해 outperforamnce 달성
Related Works
- poly encoder
- poly-encoder는 bi-encoder의 낮은 성능과 cross-encoder의 memory, time complexity의 문제를 서로 상호보완하는 방식으로 등장
- pre-computed candidate embeddings 와 m 개의 context vectors 가 score를 얻기 위한 attention 연산을 수행함.
- large size set에서 highest scoring sentence 를 찾는데에 수월
- But the drawbacks that
- the score functions is not symmetric
- computational overhead is too large for use-cases like clustering, which would require O(n^2) score computations
Model
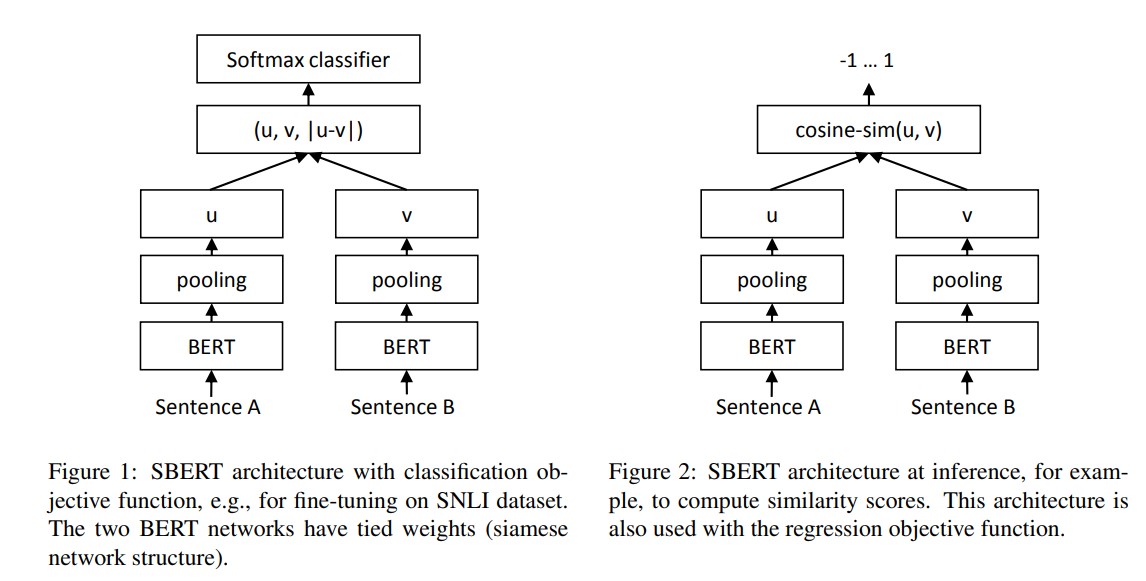
- poly-encoder는 bi-encoder의 낮은 성능과 cross-encoder의 memory, time complexity의 문제를 서로 상호보완하는 방식으로 등장
- 모델 구조는 간단하게 위와 같다. BERT/RoBERTa 모델 기반에 pooling operation 을 취하여 각각의 u, v embedding vector를 얻는다.
-
(Figure 1) classification 의 경우, $u, v, u-v $ vector를 concatenation 을 수행, trainable weight $W_t$를 곱하여 k개의 label에 대한 output을 return 한다. - (Figure 2) STS 와 같이 두 문장 사이의 similarity를 얻을 경우, 오른쪽 그림과 같이 u,v 두 개 벡터에 대한 cosine similarity 값을 구한다.
- pooling operation으로는 [CLS] token 활용하기, MEAN-pool, MAX-pool 3가지를 활용했는데, default cofing 는 MEAN 이다. (제일 성능이 좋았음)
Traning
- Objectives
- Classification Objective
- 위의 figure 1 처럼 output을 얻고, cross-entropy loss 를 취함
- Regression Objective
- u와 v 벡터에 대한 cosine-similarity 를 취하는 식으로 inference. 학습은 두 벡터에 대한 mean-squared-error loss 활용
- Triplet Objective
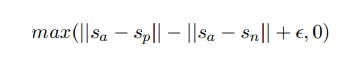
-
anchor sentence a 를 기준으로, positive sentence p 와의 거리는 가깝게, negative sentence n 과의 거리는 멀도록 학습. $ · $ 은 distance metric(Euclidean distance), epsilon(=1)은 margin을 의미한다.
-
- Classification Objective
- Training Dataset
- combination of the SNLI
- 570,000 sentence pairs annotated with the labels contradiction, eintailment, and neutral
- Multi-Genre NLI
- 430,000 sentence pairs and covers a range of genres of spoken and written text
Evaluation - Semantic Textual Similarity
- 430,000 sentence pairs and covers a range of genres of spoken and written text
- combination of the SNLI
- Unsupervised STS
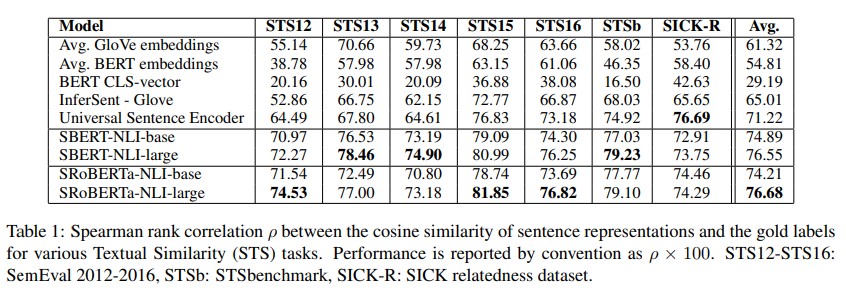
- Pearson correlation is badly suited for STS. Instead compute the Spearman’s rank correlation between the cosine-similarity of the sentence embeddings and the gold labels.
- Pearson correlation is badly suited for STS. Instead compute the Spearman’s rank correlation between the cosine-similarity of the sentence embeddings and the gold labels.
- Supervised STS
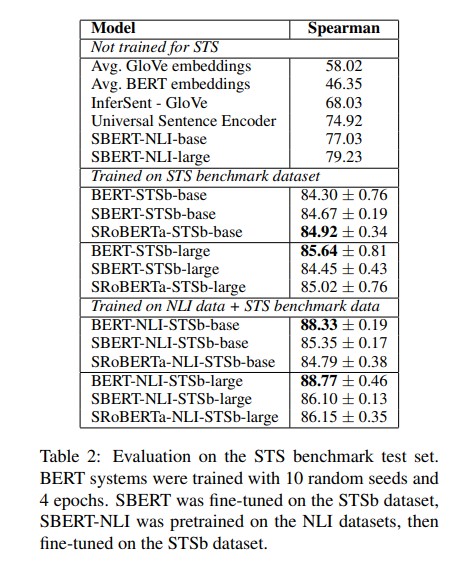
- STS benchmark dataset
- 8,628 sentence pairs from the three categories captions, news, and forums. It is divided into train (5,749), dev (1,500) and test (1,379).
- NLI training -> STSb training 한 경우와 STSb training 한 경우 두 가지 setups 를 고려함. NLI training -> STSb training setup 이 slightly better
- STS benchmark dataset
- Argument Facet Similarity
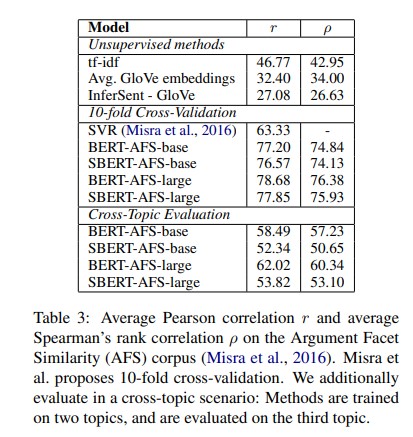
- AFS corpus
- annotated 6,000 sentential argument pairs from social media dialogs on three controversial topics: gun control, gay marriage, and death penalty.
- The data was annotated on a scale from 0 (“different topic”) to 5 (“completely equivalent”).
- To be considered similar, arguments must not only make similar claims, but also provide a similar reasoning.
- SBERT is fine-tuned using the Regression Objective Function.
- Cross-Topic Evaluation 에서 성능이 BERT 대비 저하됨.
- (OPINION) cross-topic evaluation은 학습과정에서 보지 못한 topic에 대해 evaluation 을 수행하는 것 같다.
- BERT는 2개의 sentence가 모두 들어가서 word-by-word attention 연산이 되는 반면, SBERT는 sentence 가 independently inputting 됨.
- similar 로 간주하기 위해서는, arguments가 same claim과 same reasoning 다루어야 함.
- SBERT는 unseen topic에 대해 similar claims and reasons를 vector space에 잘 mapping 시키지 못해 성능 하락인 것으로 보임.
- AFS corpus
- Wikipedia Sections Distinction
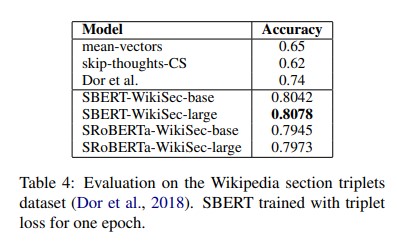
- Dor et al. assume that sentences in the same section are thematically closer than sentences in different sections.
- weakly labeled sentence triplets
- The anchor and the positive example come from the same section, while the negative example comes from a different section of the same article.
- Triplet Objective, train SBERT for one epoch on the about 1.8 Million training triplets and evaluate it on the 222,957 test triplets
- we use accuracy: Is the positive example closer to the anchor than the negative example?
Reference
- Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks