Attention Branch Network review
Learning of Attention Mechanism for Visual Explanation, 2018
이번 포스트는 지난 6개월간 인턴 생활을 하며 흥미롭게 읽었던 논문들 중 하나인 Attention Branch Network : Learning of Attention Mechanism for Visual Explanation 을 리뷰하는 포스트를 해보려 합니다. 지난 KIST-Europe 인턴 생활동안 Attention의 기술에 대해 관심을 두고 파고들었고 자연어처리에서 사용되는 attention 기법과 컴퓨터 비전에서 처리되는 attention 방법론에 대해 많은 literature study를 했었습니다. 이번 논문은 그런 논문들 중 하나로 소개해 보고자 합니다.
들어가며
모델이 클래스를 예측하는 데에 있어 이미지의 어느 부분을 통해 모델이 레이블을 예측했는지를 시각적으로 제시하며 이해를 도와주었던 Class Activation Mapping 에 관한 논문은 visual explanation을 제시하면서 뜨거운 관심을 받았습니다. 한편, activation map 계산을 위해 classifier 단을 FC층이 아니라 Convolution layer와 Golbal Average Pooling layer를 사용해야만 했습니다. 따라서 activation map을 추출할 수 있는 강점 대신, 분류 성능이 하락할 수 밖에 없는 점을 감수해야만 했습니다. (이 점을 개선하여 gradient-weighted 방식으로 CAM을 구현할 수 있는 grad-CAM 논문을 함께 참고하시면 많은 도움이 될 것이라 생각합니다! )
한편, 소개하고자 하는 논문의 연구진들은 CAM의 단점을 보완하고자 새로운 Model Architecture를 제안하게 됩니다.
주요기여 : Attention Bracnch Network를 도입하여 Attention region이 성능을 개선시키도록 하였습니다. visual explanation과 image recognition 에 대해 end-to-end 방식으로 학습 가능하도록 구성하였습니다.
결과 : ABN 모델은 image recognition tasks(image classification, fine-grained recognition, multiple facial attribute recognition)에서 당시의 baseline model들에 비해 outperformance를 내게 됩니다.
Main Idea
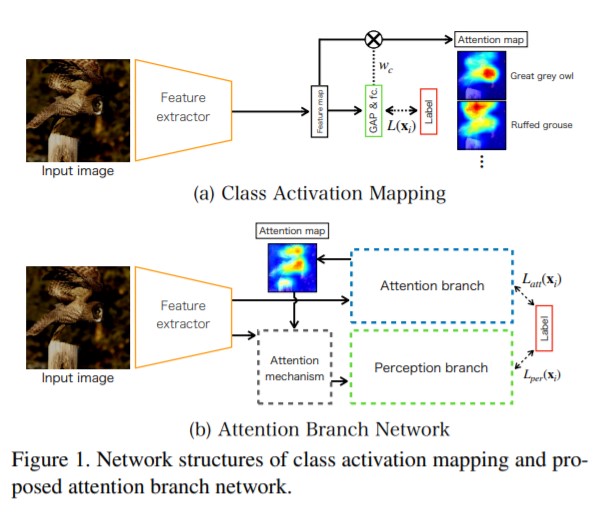
논문에서 제시하는 간단한 architecture는 Figure 1 에서 (b)와 같습니다. CAM에서는 classifier의 구조가 제약적이라는 단점이 있어, 이를 보완하며 Attention map을 이용해 오히려 분류 성능을 높이고 , 뿐만 아니라 Attention map을 뽑는 과정 또한 trainable 하게 구성하게 됩니다.
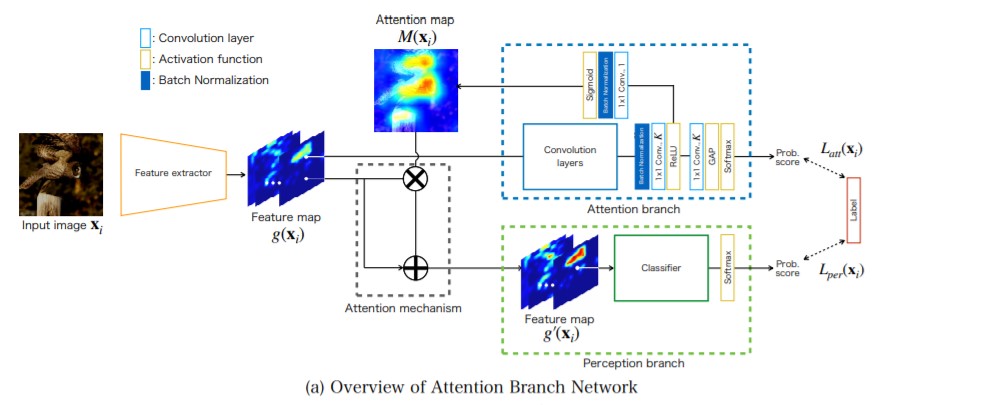 모델의 구조를 조금 더 자세하게 들여다보면 위의 Figure와 같습니다. 만약 기존의 모델같았더라면 Feature Extractor 이 후, classifier 역할을 하는 layer들로 구성이 되어 테스크의 결과를 내게 될테지만, 위의 구조에서는 Feature Extractor 이후의 Feature map이 두 갈래로 갈라지게 됩니다. 그 이후의 갈래를 순차적으로 살펴보고자 합니다.
모델의 구조를 조금 더 자세하게 들여다보면 위의 Figure와 같습니다. 만약 기존의 모델같았더라면 Feature Extractor 이 후, classifier 역할을 하는 layer들로 구성이 되어 테스크의 결과를 내게 될테지만, 위의 구조에서는 Feature Extractor 이후의 Feature map이 두 갈래로 갈라지게 됩니다. 그 이후의 갈래를 순차적으로 살펴보고자 합니다.
-
Attention Branch
Feature map 의 정보가 Attention branch로 들어오게 되면 Attentino branch 에서는 CAM과 유사하게 Convolution layer와 GAP layer를 구성하며 predicted 값을 내놓는 동시에, 다른 갈래로 Attention map을 뽑을 수 있게 됩니다. -
Attention Mechanism
Attentino Mechanism에서는 기존의 Feature map 정보와 Attentino map 의 정보를 element wise 곱을 통해 정보의 강세와 약세를 구별하게 됩니다. 이 후 Feature map 을 한 번 더 concatenation 해 줌으로서 이전 정보를 손실하는 것을 막게 도와줍니다. -
Perceptron branch
Perceptron branch 에서는 Attention mechanism 을 통해 새롭게 추출된 Feature map g’(x) 를 활용해 일반적인 classifier와 같이 Fully Connected layer를 활용해 predicted 값을 얻어내게 됩니다. -
Loss Function
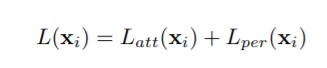 모델의 Loss function은 단순하게 두 attention branch의 loss 와 perceptron branch loss의 합으로 구해집니다. 여기서 loss 함수는 softmax와 cross entropy를 사용한 image classificatino task의 loss 함수와 동일하게 계산됩니다.
모델의 Loss function은 단순하게 두 attention branch의 loss 와 perceptron branch loss의 합으로 구해집니다. 여기서 loss 함수는 softmax와 cross entropy를 사용한 image classificatino task의 loss 함수와 동일하게 계산됩니다.
결과
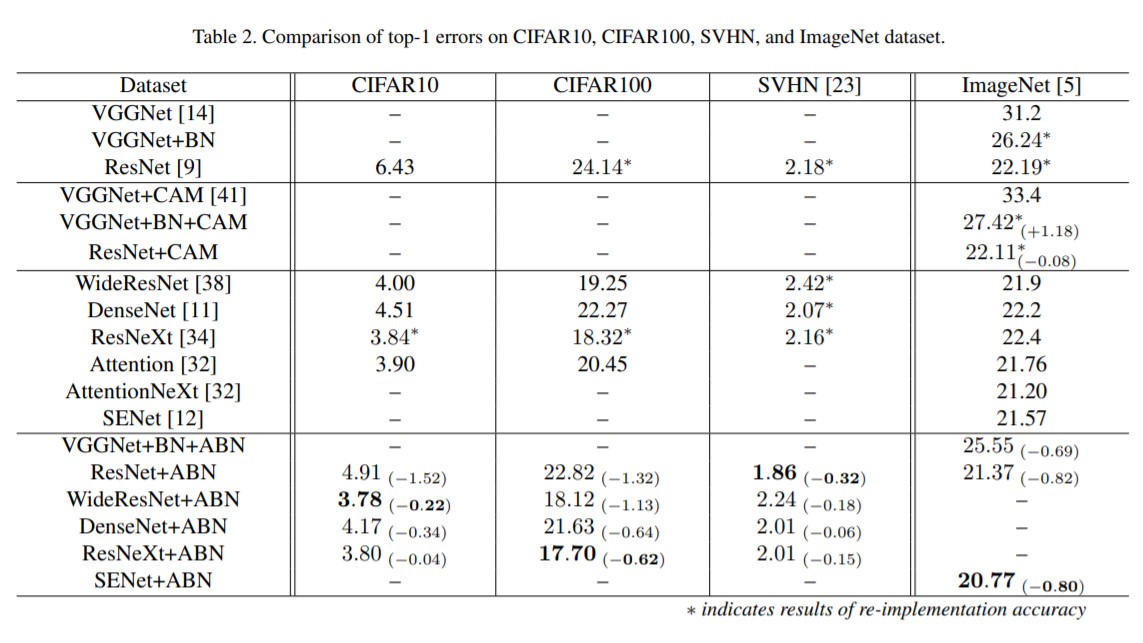
위의 Table은 여러 데이터셋에서 기존의 model들과 비교해보았을 때 Attention Branch Network를 함께 사용한 모델이 더 좋은 성능을 냄을 보여주는 테이블입니다.
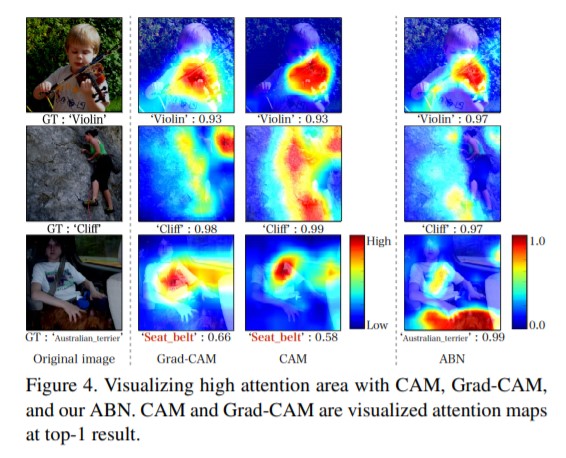
위의 figure는 CAM, Grad-CAM, ABN 모델들의 attention area를 보여줍니다. 특히 마지막 예시의 경우, 이미지에 “Seat belt” 와 “Australian terrier”가 포함되어 있으며 CAM, Grad-CAM의 경우 multiple object들을 포착하지 못하지만 ABN에서는 multiple object들을 포착하고 있음을 보여줍니다.
마치며
지금까지 Attention Branch Network 모델에 대해서 살펴보았습니다. CAM, grad-CAM 등 이후의 연구들에 이어 점진적으로 발전적인 연구들에 흥미로웠습니다. 잘못된 내용이 있다면 댓글로 남겨주시면 감사하겠습니다.