ViLBERT review
ViLBERT, Pretraining Task-Agnostic Visiolinguistic Representations for Vision-and-Language Tasks, 2019
Summary
본 논문에서는 Image 와 Text modality를 함께 학습할 수 있는 multimodal model architecture 인 ViLBERT(Vision-and-Language BERT)를 제안합니다. 아이디어를 간단히 소개하자면, visual input과 textual input 이 각각의 stream으로 입력되고, co-attentional transformer layer를 통해 서로 다른 modality 사이에서 interaction하며 학습합니다. ViLBERT는 Conceptual Captions dataset 기반의 2가지의 self-supervised learning 을 통해 pretraining을 수행하고, vision-and-language task들(visual question answering, visual commonsense reasoning, referring expressions, and caption-based image retrieval) 에 대해 transfer learning을 수행합니다. 위의 task들에서 State-Of-The-Art 성능을 보여주면서 pretrainable 하며, transferable capability를 보여주고 있습니다.
Main Idea
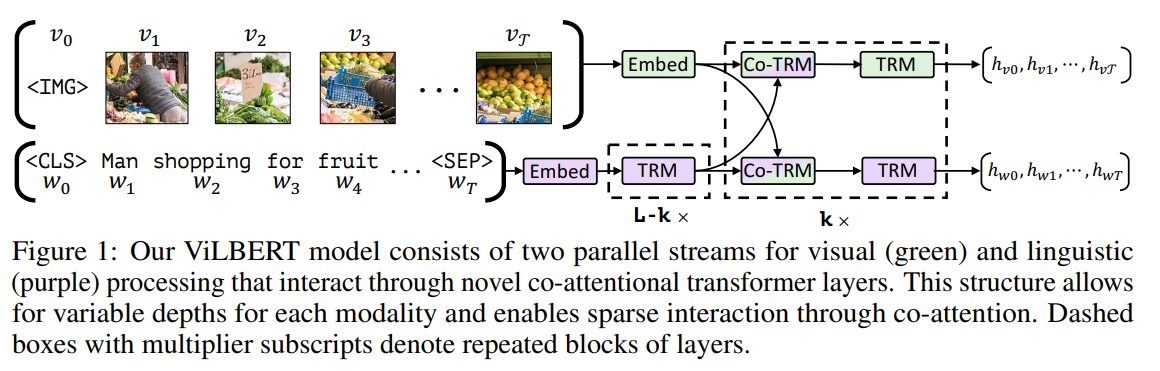
ViLBERT의 주요한 아이디어는 co-attentional transformer layer를 통해 서로 다른 modality 사이에 interative 하게 학습이 가능한 점입니다. 위의 그림과 같이 Image 와 Text 가 2 stream으로 입력되어, co-attentional transformer 를 통해 학습합니다. (TRM은 Transformer를 약자로 쓴 것입니다.)
ViLBERT는 Image를 직접 입력으로 받는 것이 아니라, pretrained Faster R-CNN 모델을 통해 region feature를 추출하고, 해당 feature들을 사용합니다. 여기에 사용되는 region feature들은 class detecion probability가 confidence threshold가 넘어야 선별되며, 위의 그림에서 $v_i$ 는 이렇게 선별된 region의 mean-pooled convolutional feature를 나타냅니다. Text를 전처리하는 방법은 BERT에서의 방법과 동일합니다.
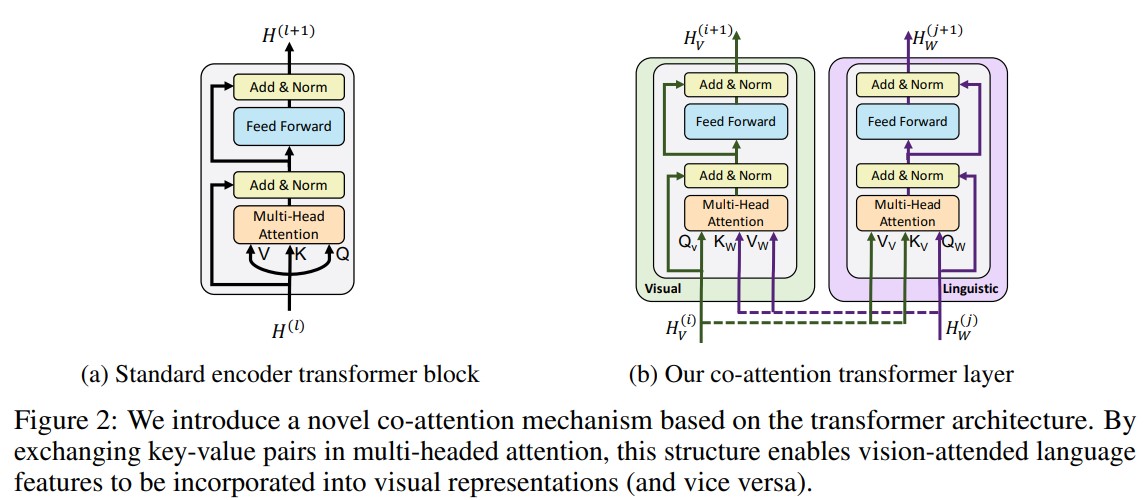
위의 그림의 (a)는 기존의 Transformer encoder 를 나타내고, (b)는 ViLBERT의 co-attentional transformer layer를 보여줍니다. (b)의 layer에서는 textual modality 에서 얻어진 K, V를 visual stream에 넣어주고, visual modality에서 얻어진 K, V를 textual stream에 넣어줌으로써 interactive 하게 학습을 수행합니다.
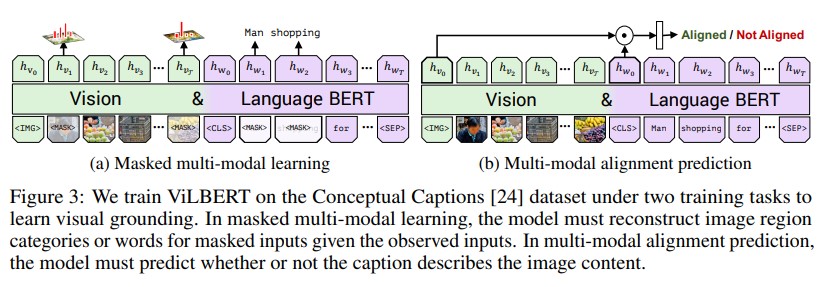
위의 사진은 ViLBERT model이 Conceptual Captions 데이터셋에 대해 pretrain된 2가지의 proxy tasks를 나타냅니다.
(a) Masked multi-modal learning 는 BERT에서의 Masked token prediction 을 수행하듯이, masked inputs에 대한 정보를 맞춰야 합니다. masked image region 에 대해서는 90%는 zero out되고, 10%만 남겨둡니다. masked text inputs 은 BERT와 동일한 방법을 사용합니다. (여기서 image 단에서 예측하는 것을 조금 더 자세하게 소개하면, 여기서 예측하는 것은 distribution over semantic classes입니다. 이에 대한 supervision은 이전에 image feature extraction에 사용된 pretrained detection model의 distribution 값을 label로 사용합니다.)
(b) Multi-modal alignment prediction 에서는 image와 caption 사이의 alignment를 check합니다. image stream의 [CLS] token처럼 취급되는 $h_{IMG}$ 와 text stream의 [CLS] token인 $h_{CLS}$ vector에 대한 element-wise product를 수행하고, binary classification 을 위한 linrea layer를 붙여, 서로 다른 modality input들 사이의 alignment 를 확인합니다. Conceptual Captions 에서는 이미 aligned pair만 제공하기 때문에, image or caption 을 random sampling 하여 negative pair 를 구성합니다.
Experiments
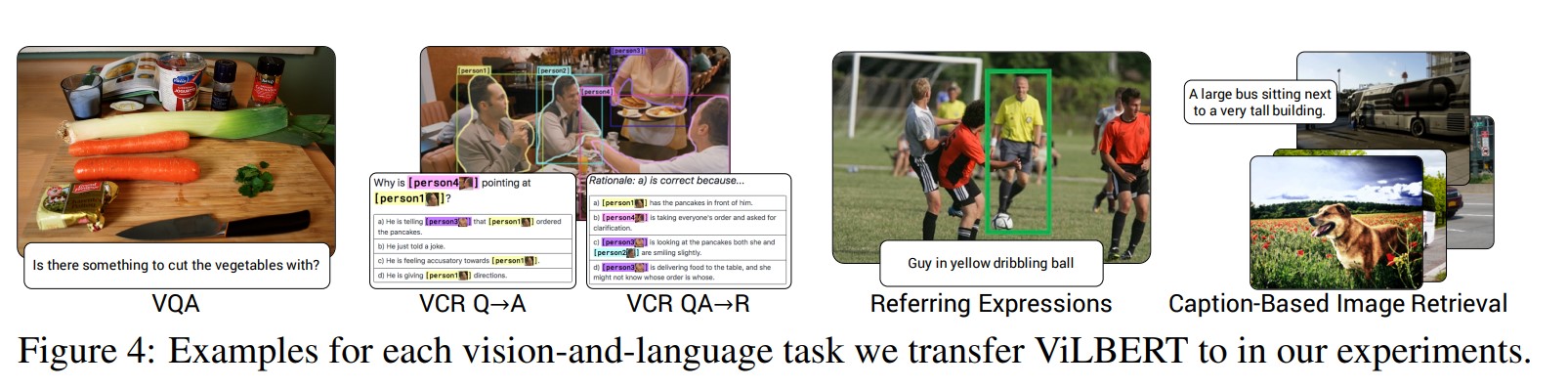
위의 사진에서는 ViLBERT가 transfer learning을 수행한 vision-language task 들을 보여줍니다.
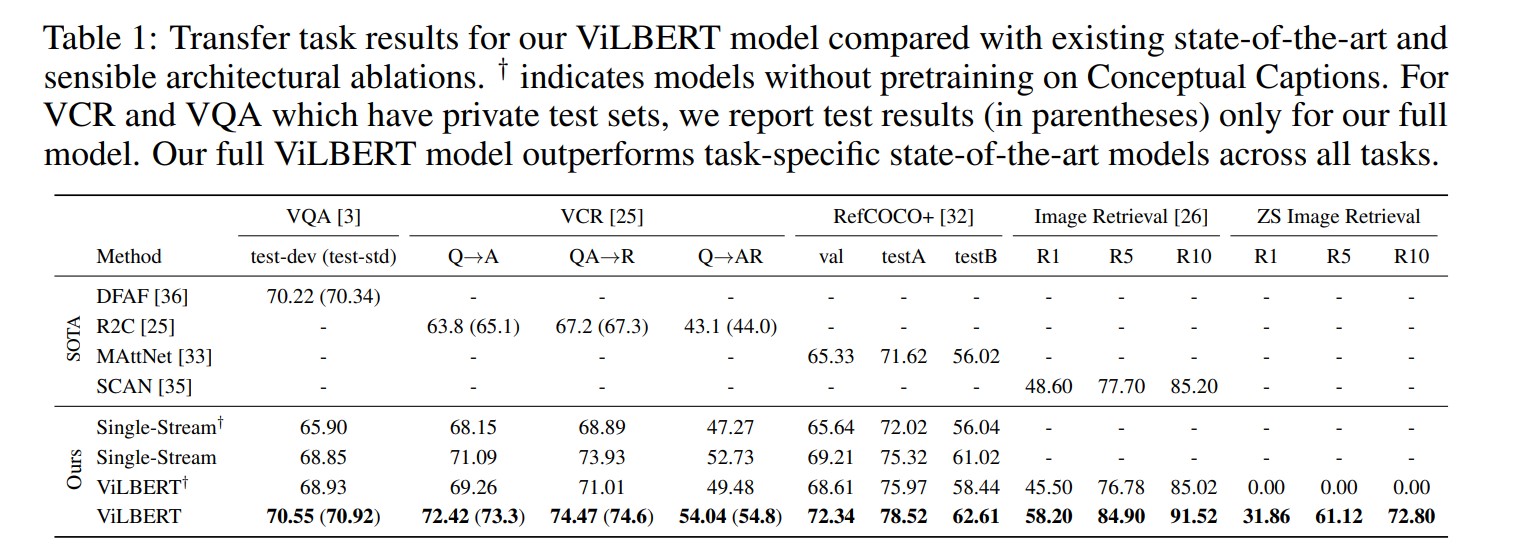
ViLBERT 를 활용한 transfer learning을 수행한 결과, 현존하는 모델들에 대한 Stage-Of_The-Art(SOTA) 달성한 결과를 보여줍니다.
이러한 결과를 통해 주요한 3가지 결과를 이야기합니다.
- ViLBERT architecture는 single stream model 에 비해 우수한 성능을 보인다.
- 본 논문의 pretraing task들은 향상된 visiolinguistic representations을 제공한다.
- VL task들에 있어서 ViLBERT를 finetuning하는 것은 powerful strategy 이다.