GPT1
- Abstract
- unlabeled data 는 labeled data 대비 양이 방대하게 많고, 적은 양의 labeled data 로 task-specific 한 모델들을 각각 만드는 것은 어렵다.
- generative pre-training 한 방법을 활용해 모델을 학습시키고, 이 후 discriminative fine-tuning 의 approach를 제안한다.
- 이 방법은 a wide range of benchmarks for natural language understanding 에서 outperformance 를 이뤘다.
- state of the art in 9 out of the 12 tasks studied.
- e.g. absolute improvements of 8.9% on commonsense reasoning (Stories Cloze Test), 5.7% on question answering (RACE), and 1.5% on textual entailment (MultiNLI).
- Motiviation
- unlabeled data 는 labeled data 에 비해서 훨씬 그 양이 많다.
- 따라서 unlabeled data 를 활용하여 언어모델을 pre-training 하고, labeled text corpora 를 통해 specific task 를 fine-tuning 해보자.
- Unlabeled Data 활용의 문제점
- Leveraging more than word-level information from unlabeled text 는 challenging 하다. (2가지 이유 때문)
- 최적화 objective 를 어떻게 설정하는 것이 transfer에 유용한 text representation 을 학습하는 것인지 불분명하다.
- these learned representations 을 target task 로 transfer 하기 위한, the most effecitve way에 대한 consensus 가 없다.
- 기존의 방법들은,
- a combination of making task-specific changes to the model architecture using intricate learning schemes and adding auxiliary learning objectives.
- Method
- a semi-supervised approach for language understanding tasks
- using a combination of unsupervised pre-training and supervised fine-tuning.
- unsupervised learnig 즉, generative 하게 문장을 만드는 방법으로 pretrinaing 을 수행하고, fine-tuning 을 수행할 때는 task specific data와 해당 label을 맞추는 확률을 극대화 하도록 하는 objective 를 활용한다.
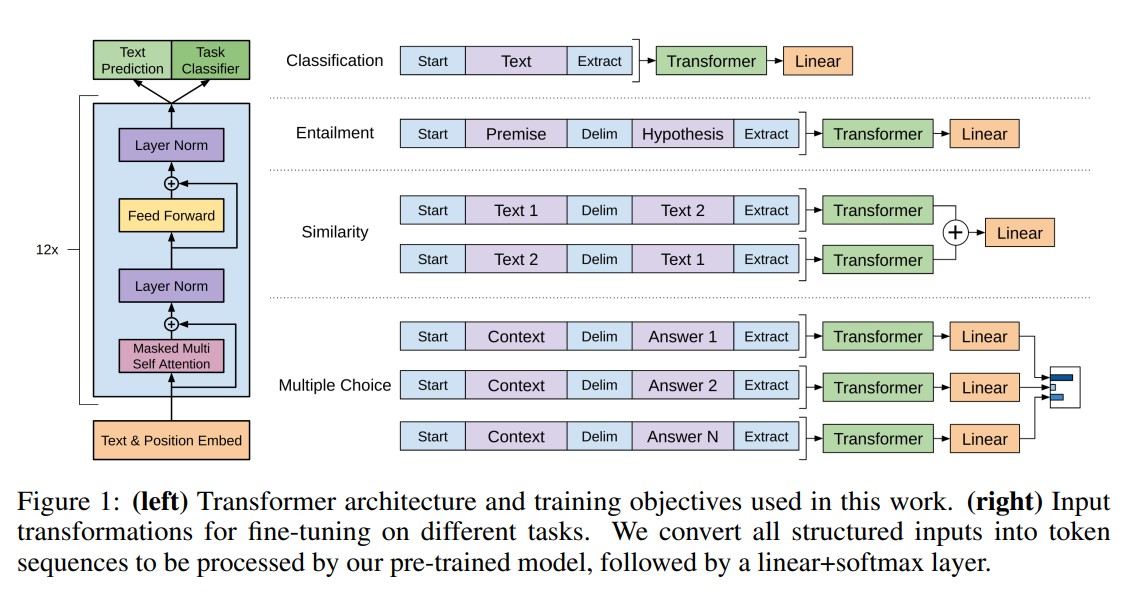
- Model Architecture

- Transformer decoder 블록만을 활용하고, 그중에서도 encoder는 안쓰기 때문에 cross-attention 이 활용되는 부분은 없다. masked multi-head attention 으로 이루어진 decoder 블록들을 활용한다.
- two stage 로 진행
- Unsupervised pre-training
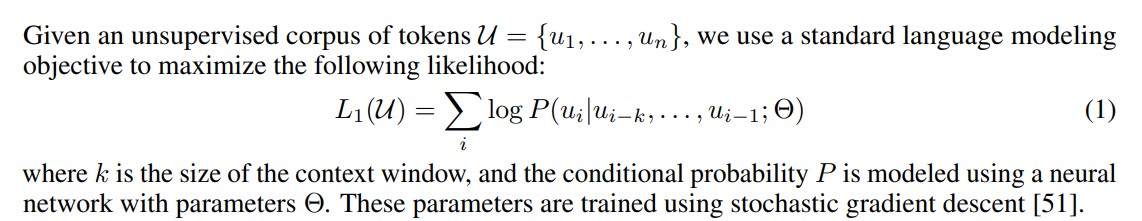
- 모델 파라미터와 이전의 context window k 만큼의 token 이 주어졌을 때, i번째 token이 발생할 likelihood를 maximize 하도록 학습한다.
- L(U) 는 unlabeled data에 대한 loss 발생을 의미한다.
- Supervised fine-tuning

- y값을 낼 때에는, final transformer block 과 linear output layer, softmax 를 활용하여 그 값을 얻는다. 또한 그 값을 likelihood maximize 방법으로 학습하도록 한다.
- L(C) 는 labeled data에 대해 발생하는 loss를 의미한다.
- Training details
- Pre-training
- Dataset
- BookCorpus dataset
contains over 7,000 unique unpublished books from a variety of genres including Adventure, Fantasy, and Romance.
- 1B Word Benchmark
- Model specifications
- Adam optimization scheme with a max learning rate of 2.5e-4. The learning rate was increased linearly from zero over the first 2000 updates and annealed to 0 using a cosine schedule.
- bytepair encoding (BPE) vocabulary
- learned position embeddingss
- Gaussian Error Linear Unit (GELU) Activation Function
- a modified version of L2 regularization proposed in [37], with w = 0.01 on all non bias or gain weight.
- Fine-tuning
- task 마다 입력 형식이 조금씩 달라서, special token을 활용하여 구분해주는 역할을 함
- transformer decoder 모델 구조는 동일하지만, output linear layer를 task마다 다른 방법으로 붙여 활용함.
- Including language modeling as an auxilary objective to the fine-tuning 의 이점
- supervised model의 일반화 성능 향상
- convergence 속도 accerlation
- Experiments
- 각 task specific transformer model architecture
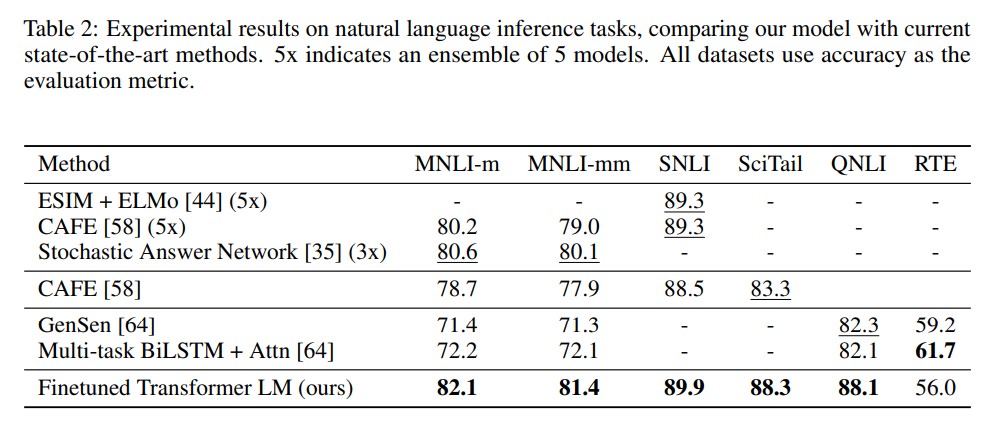
- Natural Lanugage Inference (textual entailment)
- We evaluate on five datasets with diverse sources,
- including image captions (SNLI), transcribed speech, popular fiction, and government reports (MNLI), Wikipedia articles (QNLI), science exams (SciTail) or news articles (RTE).
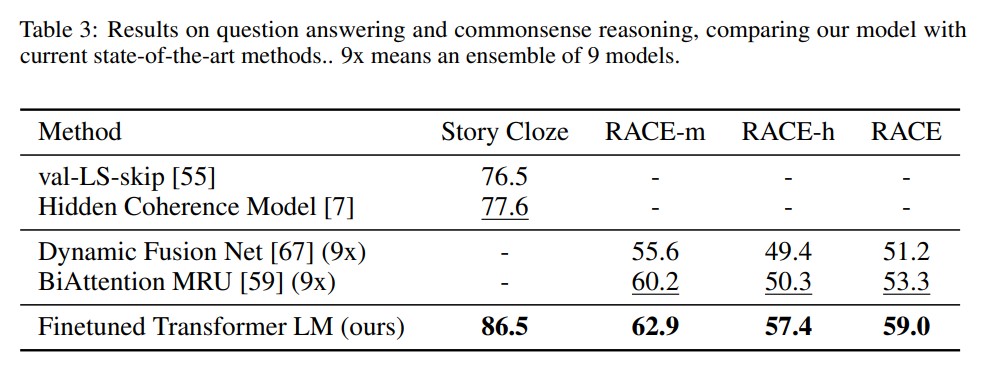
- Qeustion Answering and Commonsense Reasoning
- datasets
- RACE dataset, consisting of English passages with associated questions from middle and high school exams.
- the Story Cloze Test, which involves selecting the correct ending to multi-sentence stories from two options.
- Semantic Similarity & Classification
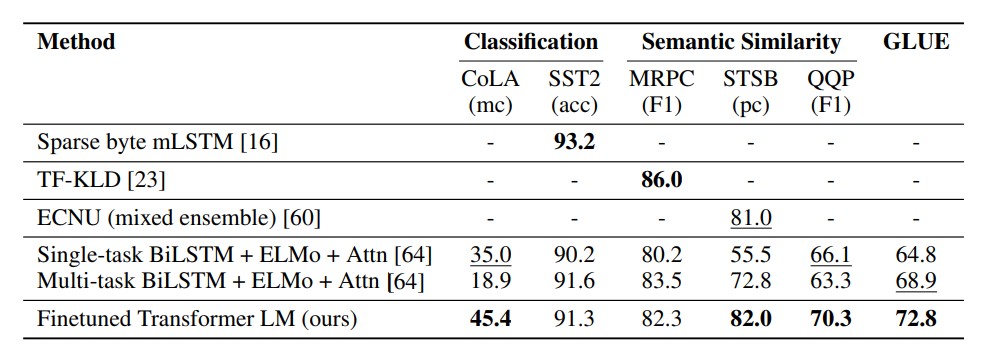
- Semantic Similarity Dataset
- the Microsoft Paraphrase corpus (MRPC) (collected from news sources)
- the Quora Question Pairs (QQP) dataset
- the Semantic Textual Similarity benchmark (STS-B)
- Classification
- The Corpus of Linguistic Acceptability (CoLA)
- contains expert judgements on whether a sentence is grammatical or not, and tests the innate linguistic bias of trained models
- The Stanford Sentiment Treebank (SST-2)
- standard binary classification task
- Analaysis
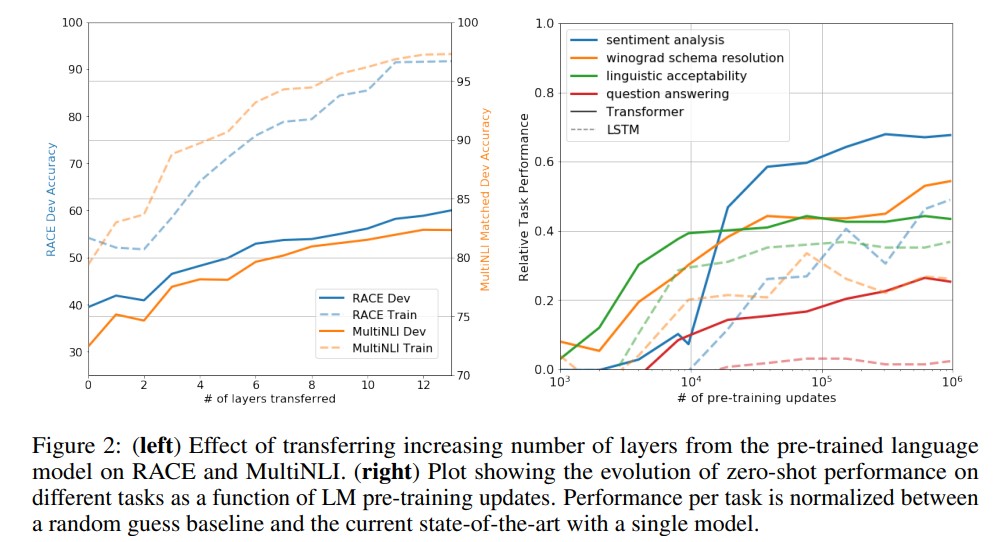
- Impact of number of layers transferred & Zero-shot performance
- decoder 블록을 쌓을수록 성능이 높아진다.
- pretraining updates 가 많아지면 성능이 높아진다. (?)
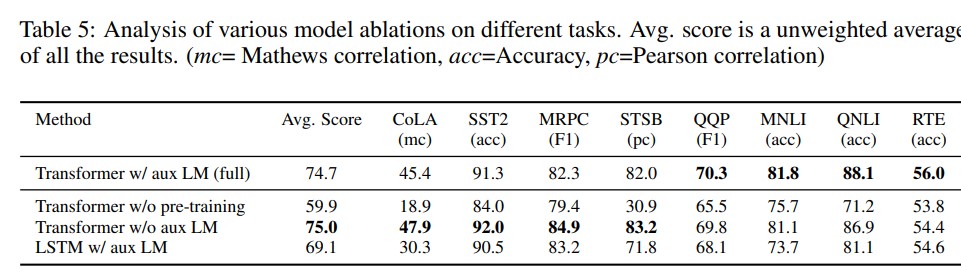
- auxiliary objective (subtask 등 다른 task의 objective term을 함께 학습에 사용하는 것)
task-specific 한 labeled dataset size가 클 때는 aux LM (task specific objective term) 이 효과가 있지만, labeled dataset size가 작을 때는 그렇게 큰 효과를 보지 못한다.
Reference