Greedy Search & Beam Search
Greedy Search 와 Beam Search 에 관한 내용을 정리합니다.
Greedy Search
- Greedy Decoding은 해당 시점에서 가장 확률이 높은 단어를 선택하는 방식
- 시간복잡도 면에서 우수 / 최종 정확도 not good
- 1, 2등 사이의 확률 분포가 차이가 미미하다면, 2등도 고려해줘야 하는데 그러지 못하고 1등만 고려함.
- 예측이 한 번이라도 틀리게 될 경우 치명적 문제 발생
- Beam Search 에서 k=1인 경우, Greddy Decoding 이 된다.
Beam Search
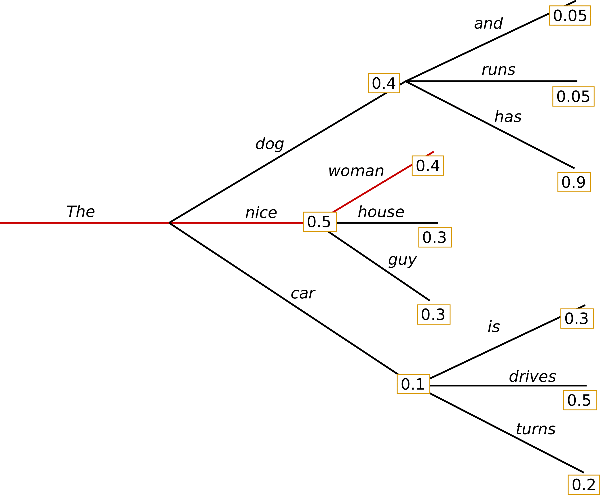
- Beam Search 는 promising beam k개를 선별하여 진행하는 방식이다.
- 가장 좋은 방법은 나올 수 있는 모든 경우의 수를 고려하여 누적 확률이 가장 높은 것을 찾는 것이지만, 이는 현실적으로 엄청난 time complexity 를 가진다.
- 이는 Greedy하게 하나만 가져가는 경우를 보완해준다.
- decoding step
-
token을 만나기 전, word by word 문장 생성 과정 1-1. token을 시작으로 하나의 time step에서 k개의 후보를 선별한다. 1-2. 다음 sequence에서 k개에 대해 k개의 후보가 또 나오면 total k*k개의 후보가 된다.
여기서 누적 확률을 기준으로 상위 k개의 후보만을 선별한다. 1-3. 이 과정을token을 만날때가지 반복 진행한다. - 어떤 후보 문장이
token을 만날 경우 2-1. 해당 문장을 제외하면, 아직 문장 생성이 진행중인 후보들은 k-1개가 될 것이다.
k+1 번째로 문장 후보로 제외되었던 후보를 포함시키고, eos를 만난 문장은 k개의 문장 중 하나로 포함시킨다. 2-2. 이와 같이token을 만난 총 k 개의 문장을 생성한다.
-