Decoding Methods For Language Generation (sampling, top-K sampling, top-p samping)
sampling, top-k sampling, top-p (nucleus) sampling 등을 정리합니다.
Sampling
- sampling 의 도입 배경
기존의 beam search는 이전 단어를 기반으로 더 높은 확률을 가지는 방향으로 단어를 선택한다.
반면, 사람의 단어 선택은 predictable하지 않고 boring 하지 않다.
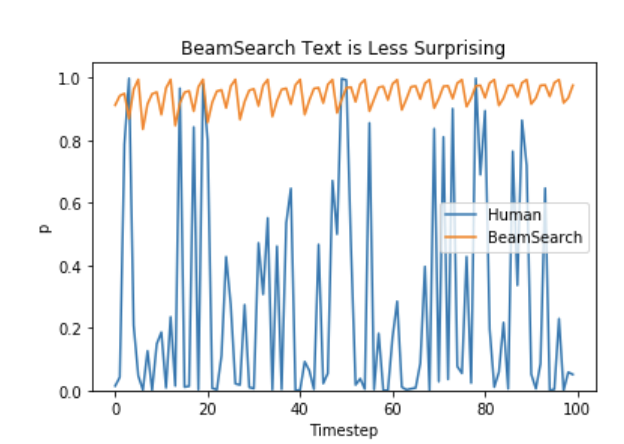
이에 좀 더 creative 하고 boring 하지 않은 단어를 선택하는 방법들이 등장하기 시작한다. - sampling 이란
sampling 방법론은 p(w_t | w_t-1:w_1) 의 확률이 주어졌을 때 randomly picking 하는 방법론이다.
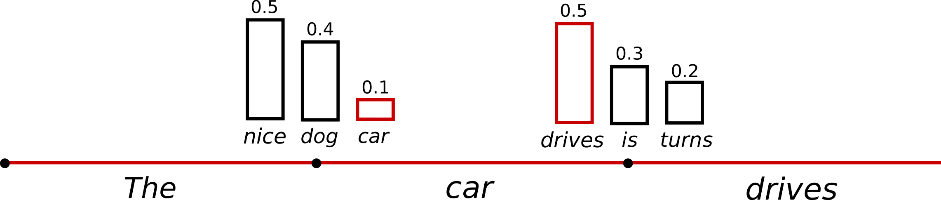
위의 그림과 같이 P(w|”The”) 에서 (“car”) 가 sampling 되었고, P(w|”The”, “car”) 에서 (“drives”) 가 sampling 되었다. - output 예시
# set seed to reproduce results. Feel free to change the seed though to get different results tf.random.set_seed(0) # activate sampling and deactivate top_k by setting top_k sampling to 0 sample_output = model.generate( input_ids, do_sample=True, max_length=50, top_k=0 ) print("Output:\n" + 100 * '-') print(tokenizer.decode(sample_output[0], skip_special_tokens=True)) """ Output: ---------------------------------------------------------------------------------------------------- I enjoy walking with my cute dog. He just gave me a whole new hand sense." But it seems that the dogs have learned a lot from teasing at the local batte harness once they take on the outside. "I take """ - 단점
위의 예시에서 “new hand sence” , “local batte harness” 같은 words들은 꽤 어색하다.
이런 단어들을 inherent gibberish (일관성 없는 헛소리) 라고 하는데, 이런 단어들이 등장할 가능성이 크다. - 단점 극복 trick
- softmax 함수의 temperature를 낮추는 방식으로 해결을 볼 수 있다고 한다.
low T -> y = softmax(x/T) 에서 x/T값이 x축에서 더 긴 range을 가짐 -> y 값들의 차이가 큼 -> sharp distribution -> deterministic
high T-> y = softmax(x/T) 에서 x/T값이 x축에서 더 짧은 range를 가짐 -> y 값들의 차이가 작음 -> flat distribution -> randomness 증가 - (my opinion) 어차피 randomly picking이라면 distribution이 sharp 하거나 flat 하거나 무슨 차이가 있는 것인지 잘 이해가 되지 않는다.
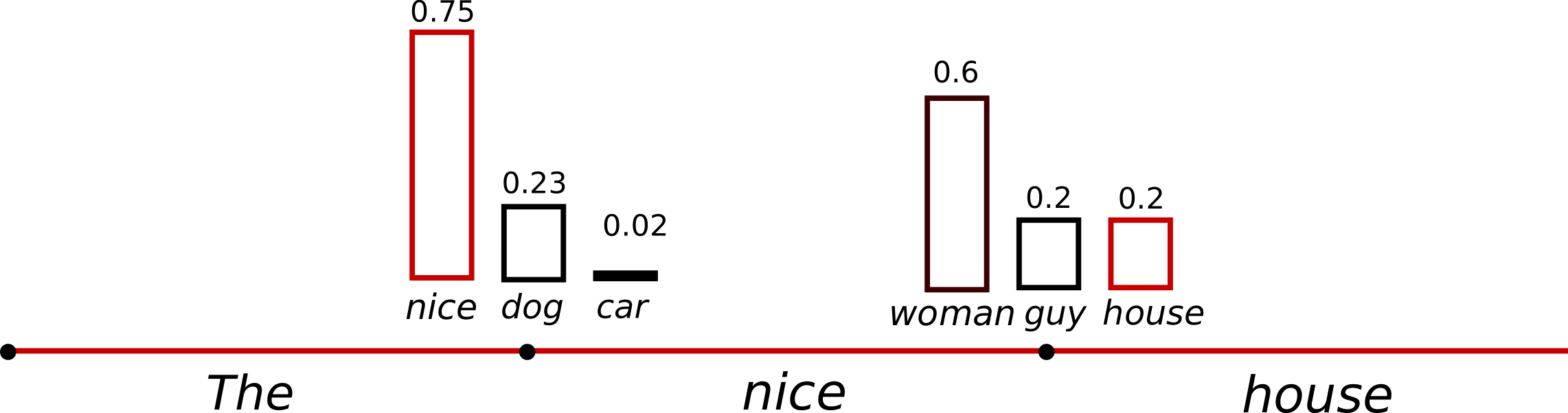
- softmax 함수의 temperature를 낮추는 방식으로 해결을 볼 수 있다고 한다.
top-k sampling
- top-k sampling 이란
most likely next words인 top K개의 words들만을 뽑고, 거기서 randomly picking을 통해 다음 단어를 뽑는다.
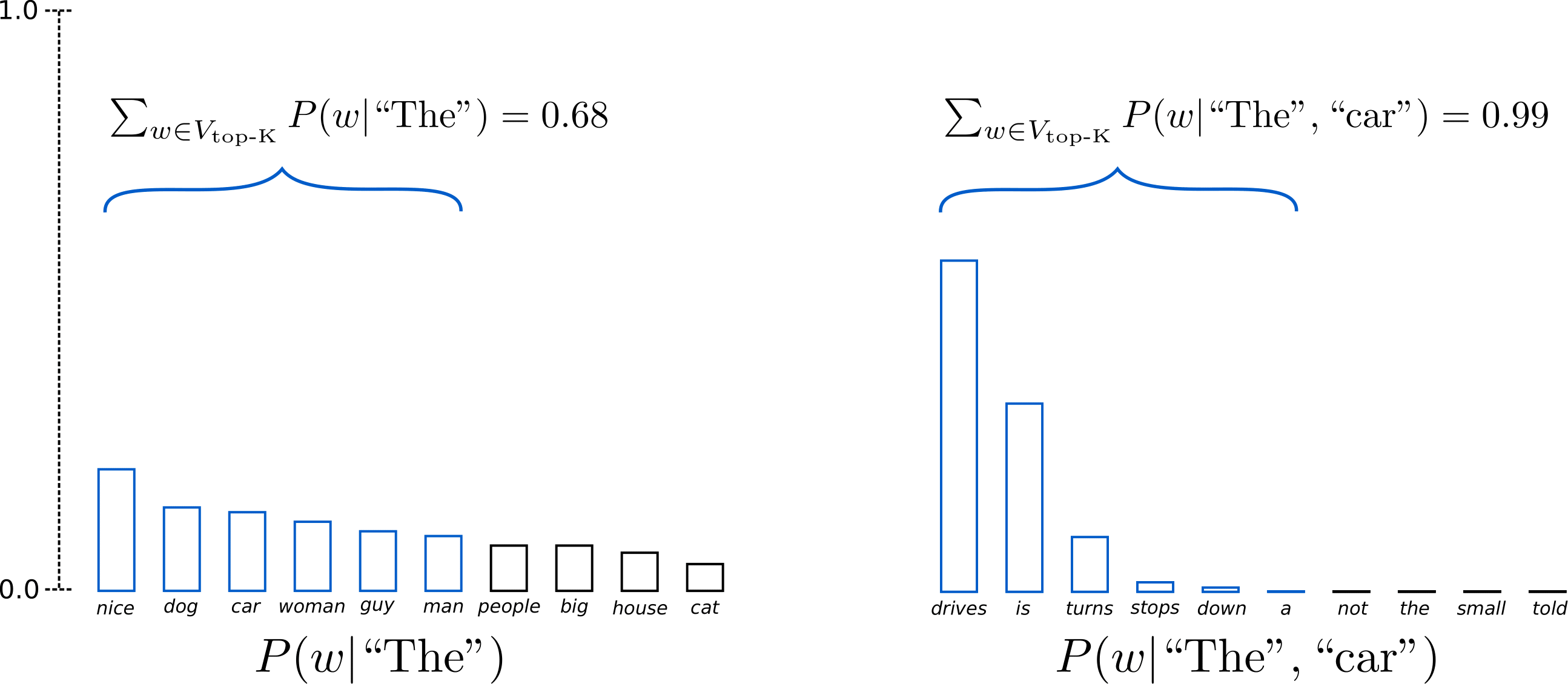
위의 그림에서 K=6으로 한 번의 step에서 6개의 단어들만을 고려한다.
왼쪽의 그래프에서는 6개의 단어만의 cumulative probability = 0.68 을 얻었다.
오른쪽의 그래프에서는 top K 개 단어만의 cumulative probability로, 즉 sum_words_top_k(P(w|”The”, “car”)) = 0.99 를 얻었다. - output 예시
# set seed to reproduce results. Feel free to change the seed though to get different results tf.random.set_seed(0) # set top_k to 50 sample_output = model.generate( input_ids, do_sample=True, max_length=50, top_k=50 ) print("Output:\n" + 100 * '-') print(tokenizer.decode(sample_output[0], skip_special_tokens=True)) """ Output: ---------------------------------------------------------------------------------------------------- I enjoy walking with my cute dog. It's so good to have an environment where your dog is available to share with you and we'll be taking care of you. We hope you'll find this story interesting! I am from """ - 단점
하지만, top K 개의 단어를 동적으로 설정할 수는 없다.
만약 sharp distribution에서 top K 개가 선별된다면, 등장하지 않아야 할 문맥상 gibberish 가 될 단어들이 선별될 수도 있다.
또한 flat distribution 에서 선별될 경우, K의 개수에 따라, 가능성 있는 단어들이 배제될 수도 있다.
top-p (nucleus) sampling
- top-p sampling 이란
top-p sampling 은, 특정한 cumulative probability threshold 값인 p 를 넘길 수 있는 smallest possible set of words를 선별한다.
이를 통해 cumulative probability 값을 충족하는 기준에 따라 매 step마다 단어의 수가 늘어나거나 줄어드는 식으로 동적 조정이 가능하다.
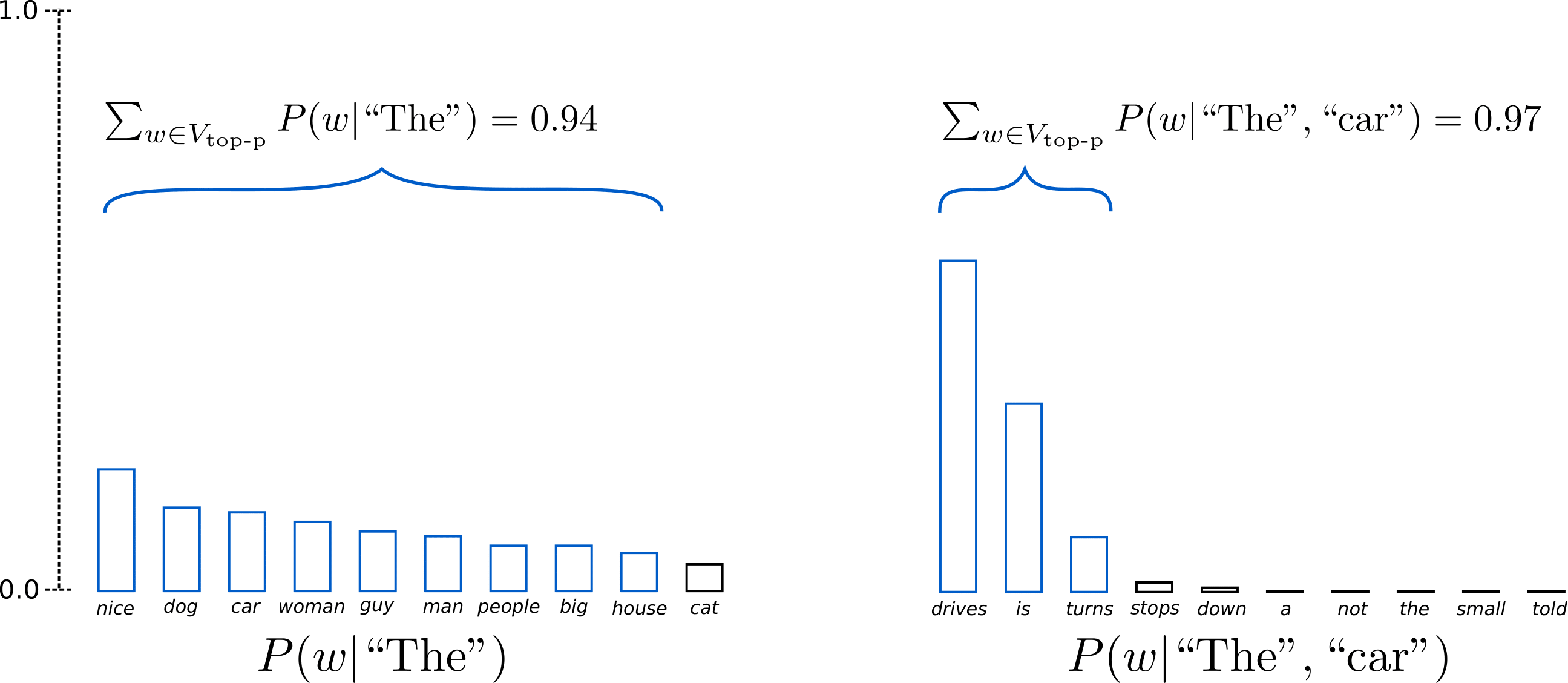
p=0.92 로 설정한 경우이다. 위의 왼쪽 그래프에서는 9개의 단어를 통해 0.94의 cumulative probability를 만들었다.
오른쪽의 그래프에서는 오직 3개의 단어만을 통해 0.97의 cumulative probability를 이루었다.
이로써 less predictable하면서, creative 한 sampling 을 보다 수월하게 할 수 있다. - output 예시
# set seed to reproduce results. Feel free to change the seed though to get different results tf.random.set_seed(0) # deactivate top_k sampling and sample only from 92% most likely words sample_output = model.generate( input_ids, do_sample=True, max_length=50, top_p=0.92, top_k=0 ) print("Output:\n" + 100 * '-') print(tokenizer.decode(sample_output[0], skip_special_tokens=True)) """ Output: ---------------------------------------------------------------------------------------------------- I enjoy walking with my cute dog. He will never be the same. I watch him play. Guys, my dog needs a name. Especially if he is found with wings. What was that? I had a lot o """