Deep Spectral Methods
A Surprisingly Strong Baseline for Unsupervised Semantic Segmentation and Localization, 2022, CVPR Oral
Abstract
- Unsupervised localization and segmentation are long-standing computer vision challenges
- that involve decomposing an image into semantically meaningful segments without any labeled data
- interesting in an unsupervised setting
- due to the difficulty and cost of obtaining dense image annotations,
- but existing unsupervised approaches struggle with complex scenes containing multiple objects.
- we
- take inspiration from traditional spectral segmentation methods by
reframing image decomposition as a graph partitioning problem. - examine the eigenvectors of the Laplacian of a feature affinity matrix from self-supervised networks.
- find that these eigenvectors already decompose an image into meaningful segments, and can be readily used to localize objects in a scene
- Furthermore, by clustering the features associated with these segments across a dataset, we can obtain well-delineated, nameable regions, i.e. semantic segmentations.
- our simple spectral method outperforms the state-of-the-art in unsupervised localization and segmentation by a significant margin
- this method can be readily used for a variety of complex image editing tasks, such as background removal and compositing.
- take inspiration from traditional spectral segmentation methods by
Method
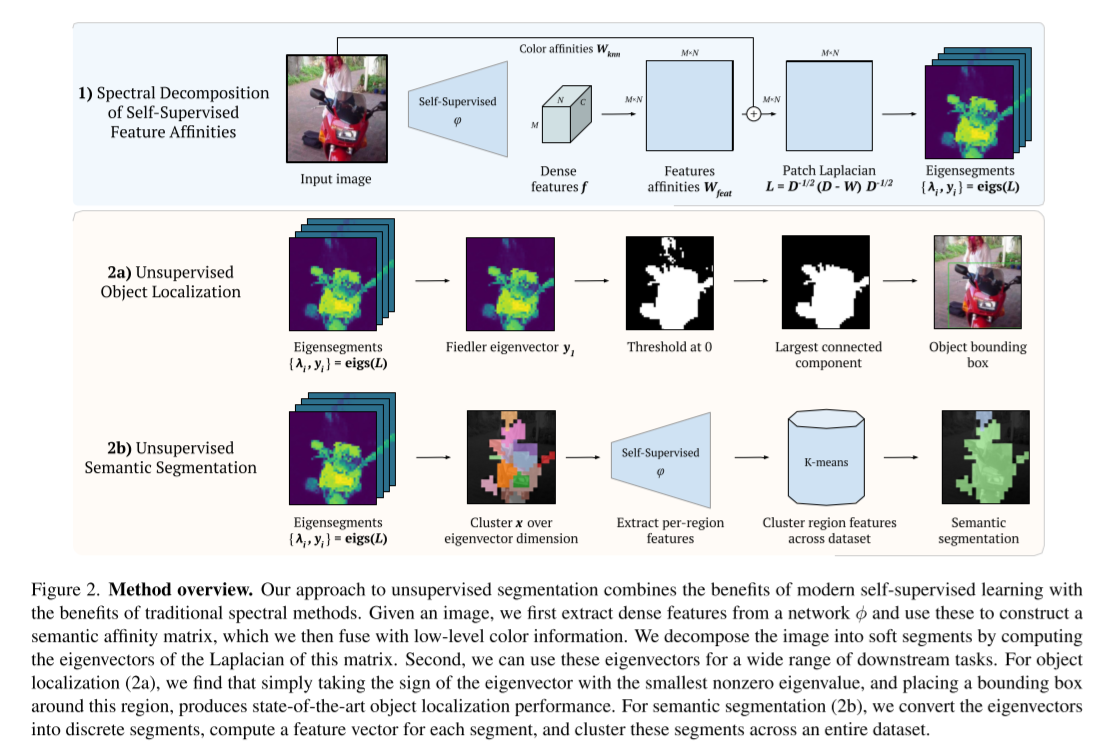
- inspiration from framed the segmentation problem as one of graph partitioning.
- Our method
- utilizes a self-supervised network to extract dense features corresponding to image patches.
- then construct a weighted graph over patches, where edge weights give the semantic affinity of pairs of patches
- consider the eigendecomposition of this graph’s Laplacian matrix
- the eigenvectors of the Laplacian of this graph directly correspond to semantically meaningful image regions.
- Notably, the eigenvector with the smallest nonzero eigenvalue generally corresponds to the most prominent object in the scene.
→ surprisingly, simply extracting bounding boxes or masks from this eigenvector surpasses the current state of the art on unsupervised object localization/segmentation across numerous benchmarks.
- Next, we propose a pipeline for semantic segmentation
- convert the eigen-segments into discrete image regions by thresholding
- associate each region with a semantic feature vector from the network
- yielding semantic (pseudo-) labels
- Lastly, we perform self-training using these labels to refine our results
- evaluate against the ground truth segmentations.
→ performs well on complex images!