DeBERTa, Decoding-enhanced BERT with Disentangled Attention
Disentangled Attention, Enhanced Mask Decoder를 활용한 DeBERTa 논문을 리뷰합니다.
Summary
- 본 논문에서는 Disentangled Attention 과 Enhanced Mask Decoder 를 활용하여 BERT & RoBERTa 의 성능 도약을 시도하였다.
- Disentangled Attention 은 context 와 position 정보를 explicit 하게 나누어서 연산을 수행한다.
- Enhanced Mask Decoder 는 pre-training 과정에서 각 단어에 대한 absolute position 정보를 활용한다. softmax layer를 거치기 전에 additional information 을 더해준다.
- Disentangled Attention 은 context 와 position 정보를 explicit 하게 나누어서 연산을 수행한다.
- 또한 model의 generalization performance를 높이기 위해 virtual adversarial training을 통해 fine-tuning 을 수행하였다.
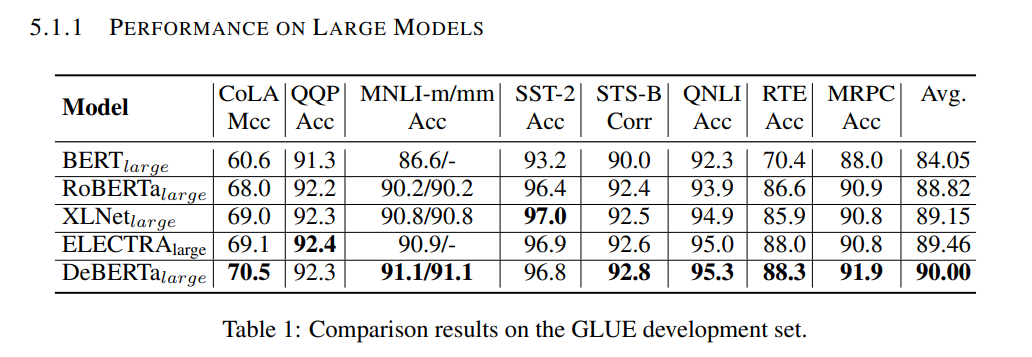
- 성능은 RoBERTa-Large 모델과 비교했을 때, training data의 절반만 학습한 DeBERTa 가 다양한 NLP task에서 성능 개선을 달성했다. (MNLI by +0.9% (90.2% vs. 91.1%), on SQuAD v2.0 by +2.3% (88.4% vs. 90.7%) and RACE by +3.6% (83.2% vs. 86.8%)
Main Contribution
-
Disentangled Attention
hidden vector 를 contents를 포함하는 vector와 position 을 포함하는 vector로 나눈다.
attention score를 얻을 때, content-to-content, content-to-position, position-to-content 의 element-wise summation 을 통해 attention score 를 얻는다.

위와 같이 4가지의 term으로 구성되며, 저자들은 단어 사이의 attention weights 가 content 뿐만 아니라 relative position 에 대한 부분을 고려해 줘야 하기에 position-to-content term을 고려해야 한다고 말한다.

각 i와 j token 사이의 Attention score 는 위의 cross attention score 의 합으로 이루어진다.
content-to-content : i에서의 query content 와 j에서의 key content 사이 attention weight 연산
content-to-position: i에서의 query content 와 j에서의 key relative position 사이 attention 연산
position-to-content : j 에서의 query relative position 과 j 에서의 key content 사이
( opinion. position-to-content 에서 $Q_{\delta(i,j)}^r {K^c_j}^T$) 로도 쓸 수 있는거 아닌가? ) -
Enhanced Mask Decoder (EMD)
relative positional information을 활용되었지만, absolute positional information은 활용되지 않았다.- ex
“a new store opened beside the new mall” 이라는 문장에서 store 와 mall 이라는 단어가 masking이 되었을 때,
두 단어 모두 앞에 new라는 단어의 등장으로, 어떤 단어가 해당 위치에 와야 하는지 판별하기 어렵다고 논문에서는 주장한다.
이에 absolute positional information을 Transforer layer 이후, softmax 를 지나기 전 포함시킨다. 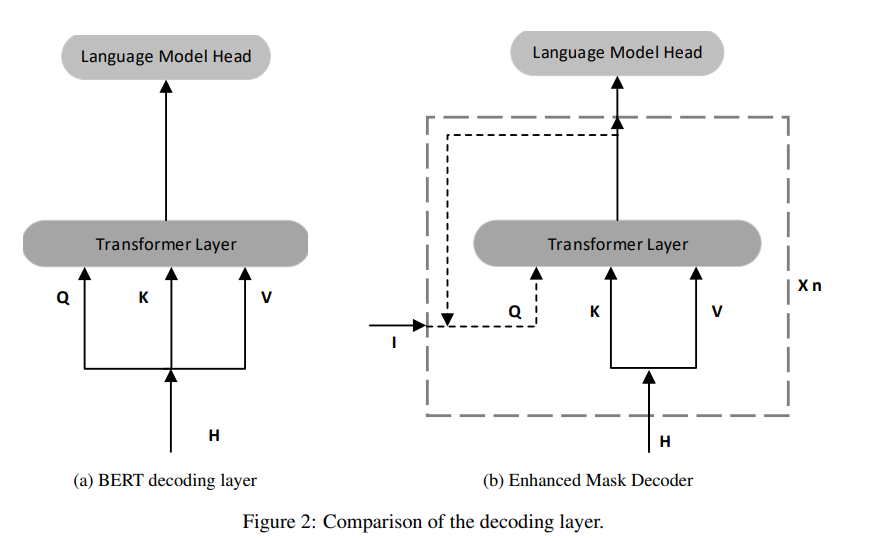
- ex
Experiment
- performance of large models
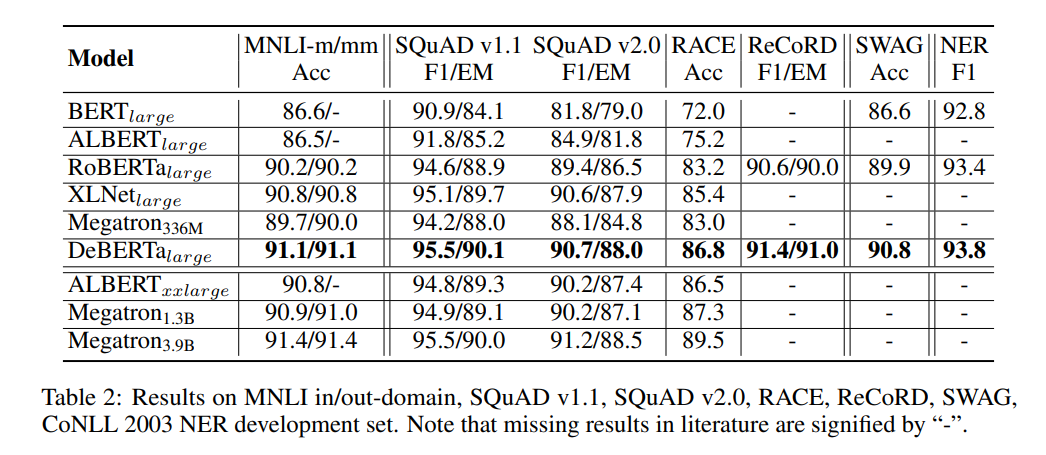
- Results on MNLI in/out-domain
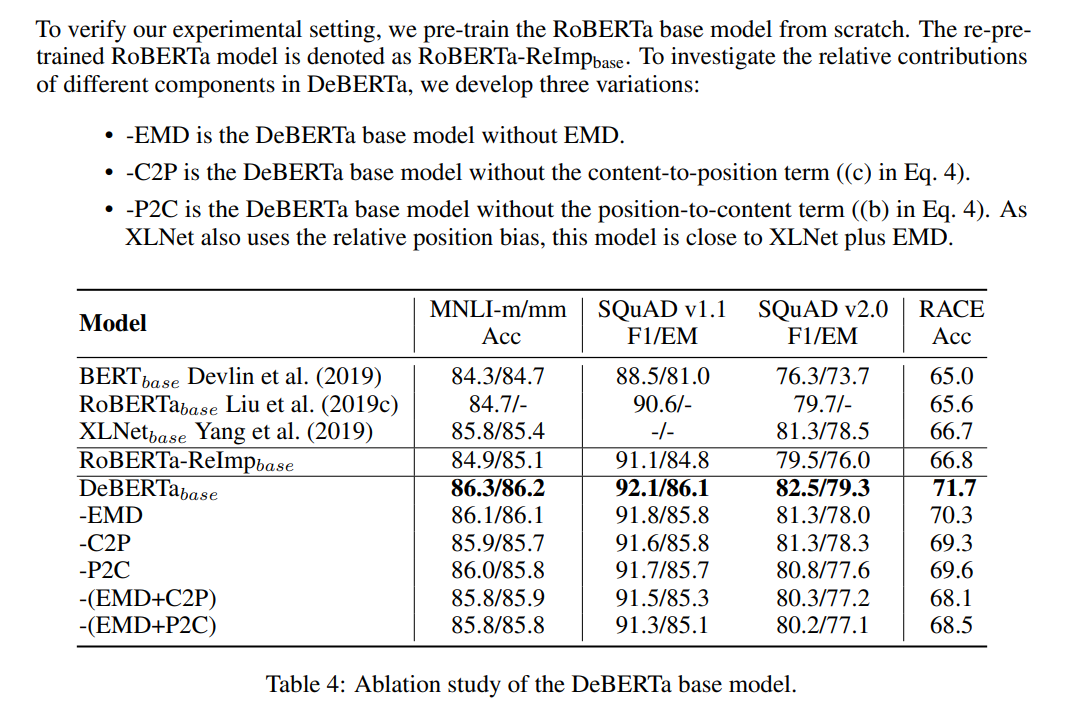
- Ablation Study of DeBERTa base model
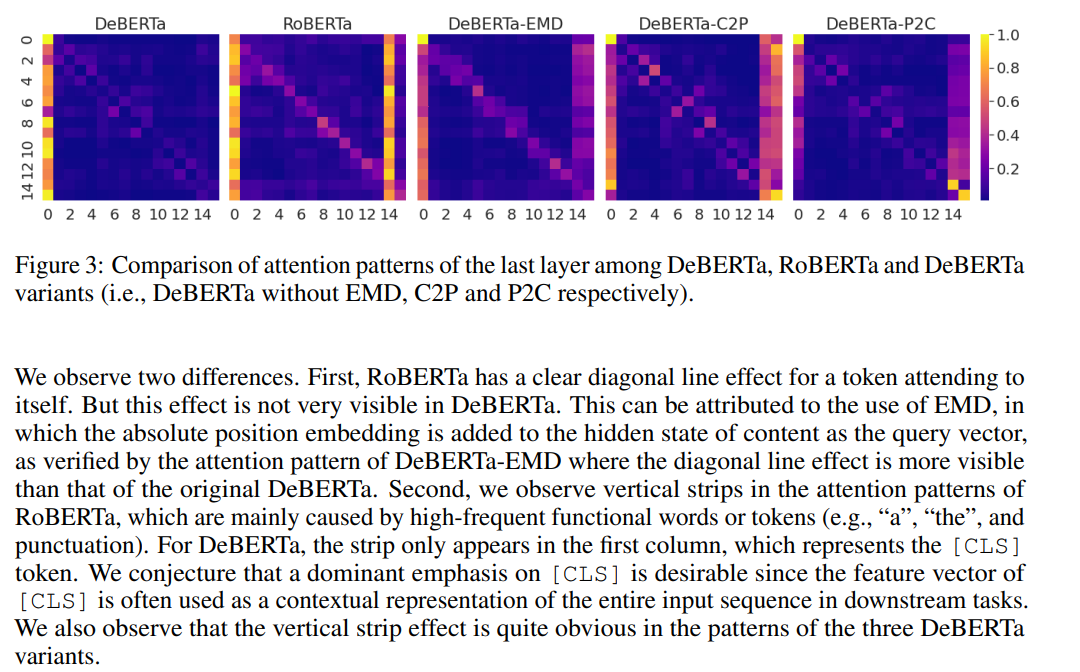
- Comparison of attention patterns of the last layer