Natural Language Generation Metric 정리
자연어 생성을 평가하는 Metric 에 대해 정리합니다.
Perplexity
-
단어 그 자체로는 당혹감, 고난 등의 뜻을 가지고 있다.
모델이 문장을 생성할 때 얼마나 확신을 가지고, 혹은 가지기 못하고 해당 문장을 생성했는지를 말한다.
모델이 확신을 가지고 생성했으면 그 확률값은 크게 되고, 그 값의 역수를 취하기 때문에, 낮을수록 더 나은 performance를 의미한다. -
수식
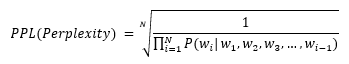
BLEU
- BLEU score 는 크게 두 부분으로 구성된다.
- Brievity Penalty * Precision
-
Brievity Penalty
= min (1, output length / reference length)
reference length 에 비해서 생성된 output length 가 더 짧다면, 이것은 더욱 낮은 값을 갖는 penelty 를 가져야 마땅하다. -
Precision Precision 의 값을 계산할 때는 n-gram (n=1,2,3,4) 의 값이 reference 와 얼마나 일치하는지를 연산한다.
ret = 1 for n in [1,2,3,4] : ret *= precision(n) ret = sqrt(sqrt(ret))
-
-
수식

- 단점
얼마나 reference 단어와의 일치하는지를 파악함, 따라서 단어의 유사성을 판단하지 못함.
전체적인 문장의 의미가 잘 반영된 지표로 보기는 어려움
METEOR(Metric for Evaluation of Translation with Explicit ORdering)
- BLEU 의 보완격
- Precision 뿐만 아니라 recall 값을 연산함
- 다른 가중치를 적용한 둘의 조화평균을 활용 (???) (어떤 것들 사이의 조화평균을 말하는 건지 불분명하다. 문맥 상으로는 precision 과 recall의 조화평균으로 해석된다.)
- 오답에 penalty 부과
- 여러 단어나 구 등을 정답으로 처리하는 등의 방법 활용
SSA(Sensible and Specificity Average)
- 자율발화 모델에 대한 평가 지표
- 사람이 직접 발화 모델과 대화를 하며 Sensibleness 와 Specificity 를 평가
- Sensibleness
모델의 답변이 얼마나 합리적인지를 binary 로 답변 - Specificity
모델의 답변이 단답형이 아니고, 구체적인지 여부를 binary 로 답변 - 0과 1 의 값만을 활용하여 평균낸 값을 취한다.
Reference
- https://blog.testworks.co.kr/nlp-generation-evaluation/